提交 Hive SQL
本小节主要介绍如何在 Hive 数据仓库中创建数据库和表,并向表中载入数据,提交 HQL 查询数据。
Hive 是一个基于 Hadoop 的数据仓库工具,可将结构化的数据文件映射成一张数据库表,将 SQL 语句转换成 MR/Spark 任务,进行复杂的海量数据分析。
前提条件
-
已获取管理控制台登录账号和密码,且已获取集群操作权限。
-
已创建 QingMR 集群,且集群状态为
活跃。 -
已打通集群网络,使集群云服务器能面向互联网提供服务。例如使用端口转发或 VPN 等方式打通网络,详细操作请参见访问组件 Web 页面。
启用 Hive 服务
Hive 的 Hive Metastore 和 HiveServer2 服务已经在主节点配置完成(默认关闭),您不需要手动配置。只需设置配置参数开启 Hive 为 true 就可以启动这两个服务,然后即可在 Client 节点运行 Hive 命令行使用 Hive。
-
通过 Web 浏览器登录青云QingCloud 管理控制台。
-
选择产品与服务 > 大数据服务 > 大数据引擎 QingMR,进入集群管理页面。
-
选择目标集群,点击目标集群 ID,进入集群详情页面。
-
选择配置信息 > 参数配置页签,点击批量修改参数值。
-
设置开启 Hive 参数为
true,点击保存。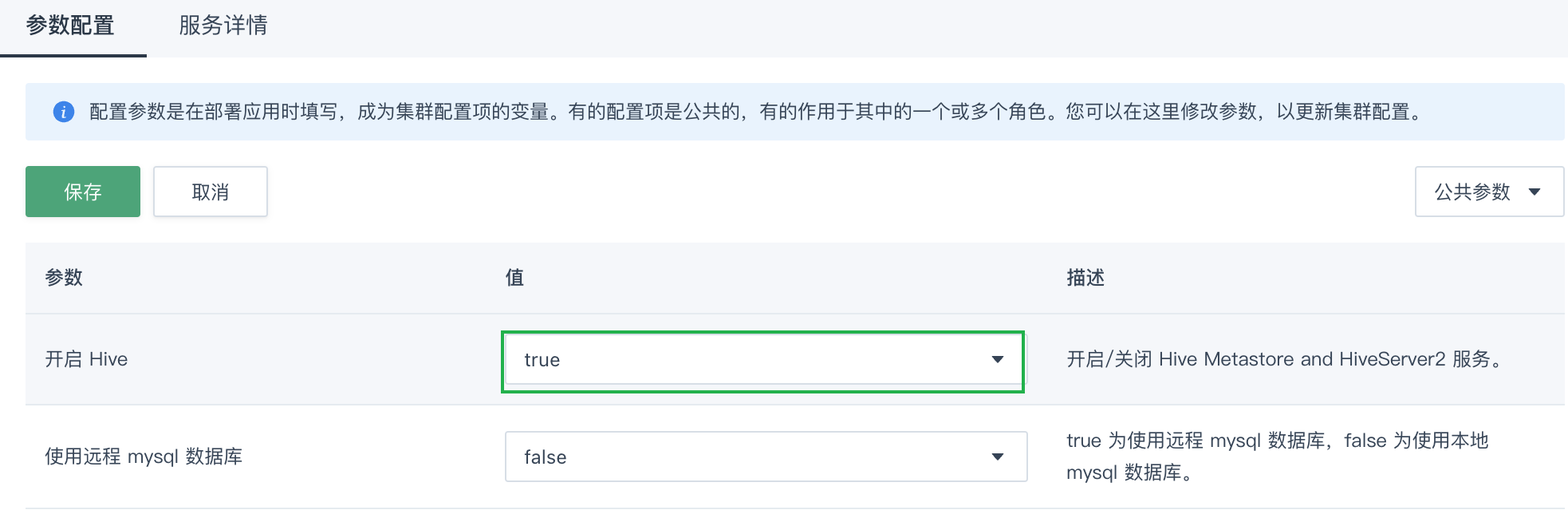
-
在弹出的提示窗口中,点击确定即可。
配置 Hive 执行引擎
Hive 支持 mr 和 spark 两种执行引擎(其中 spark 引擎从 QingMR 1.3.0 开始支持,并且作为默认执行引擎)。
本节以 spark 引起为例进行介绍,如果您需要切换执行引擎,请参见 Hive 使用指南的 Hive 执行引擎。
以 spark 作为 Hive 的执行引擎 ,在操作 Hive 之前请先在 hdfs 上创建相应的用户目录。
例如以用户 ubuntu 操作 Hive:
-
在 Client 节点以用户 ubuntu 执行以下命令,切换到 root 用户。utuntu 初始密码为
p12cHANgepwD。sudo su -
以 root 用户执行以下命令,在 hdfs 上创建 ubuntu 用户目录。
/opt/hadoop/bin/hdfs dfs -mkdir -p /user/ubuntu/ /opt/hadoop/bin/hdfs dfs -chown -R ubuntu:ubuntu /user/ubuntu/
连接 Hive
在 QingMR 集群中连接 Hive 有两种方式:通过 Hive CLI 客户端、通过 Beeline 客户端。
本节以 Hive CLI 客户端 为例进行介绍,Beeline 客户端的详细操作,请参见 Hive 使用指南的 通过 beeline 执行 HQL。
在 Hive 数据仓库中创建数据库
在 Hive 中创建数据库需要以 root 用户进行操作。
-
以 root 用户执行以下命令,在 root 下创建一个名为 test 的数据库。
/opt/hive/bin/hive -e "create database test;"创建数据库执行成功后会显示执行时间。
-
以 root 用户执行以下命令,将数据库 test 的拥有者更改为 ubuntu。
说明 在实际生产环境中,通过 root 用户创建数据库后,建议立即更改数据库的所有者,避免以 root 用户执行 Hive 语句。
/opt/hadoop/bin/hdfs dfs -chown -R ubuntu /user/hive/warehouse/test.db
在 Hive 的数据库中创建表
-
以 root 用户执行以下命令,切换到 ubuntu 用户。
su ubuntu -
以 ubuntu 用户执行以下命令,启动 CLI。CLI 中的用户身份是启动 CLI 时 Linux 所用的用户身份。
/opt/hive/bin/hive -
执行以下命令,查看创建的数据库 test,并切换到 test 数据库。并在 test 数据库下创建一个 invites 表,包含两个普通列和一个分区列。
# 查看创建的数据库,可以看到目前 Hive 数据仓库中的数据库名 SHOW DATABASES; # 切换到 test 数据库 USE test; # 在 test 数据库下创建一个 invites 表,包含两个普通列和一个分区列 CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING); # 查看创建的 invites 表: SHOW TABLES;
向 Hive 中的表载入数据
# 向创建的 invites 表载入数据,数据源使用本地文件。
LOAD DATA LOCAL INPATH '/opt/hive/examples/files/kv2.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-15');
LOAD DATA LOCAL INPATH '/opt/hive/examples/files/kv3.txt' OVERWRITE INTO TABLE invites PARTITION (ds='2008-08-08');执行 HQL 查询数据
# 查找invites表中 ‘ds=2008-08-08’ 的 ‘foo’ 列的所有内容:
# 这里并没有执行结果导出语句,因此查询的结果不会保存在任何地方,只是从CLI中显示出来。
SELECT a.foo FROM invites a WHERE a.ds='2008-08-08';
# 执行运算,计算invites表中,’ds=2008-08-15’的‘foo’列的平均值:
# Hive服务将自动把HQL查询语句转换为MapReduce运算,并调用Hadoop集群进行计算。您也可以在yarn监控中查看该语句的执行进度。
SELECT AVG(a.foo) FROM invites a WHERE a.ds='2008-08-15';查看 Hive 运行状态
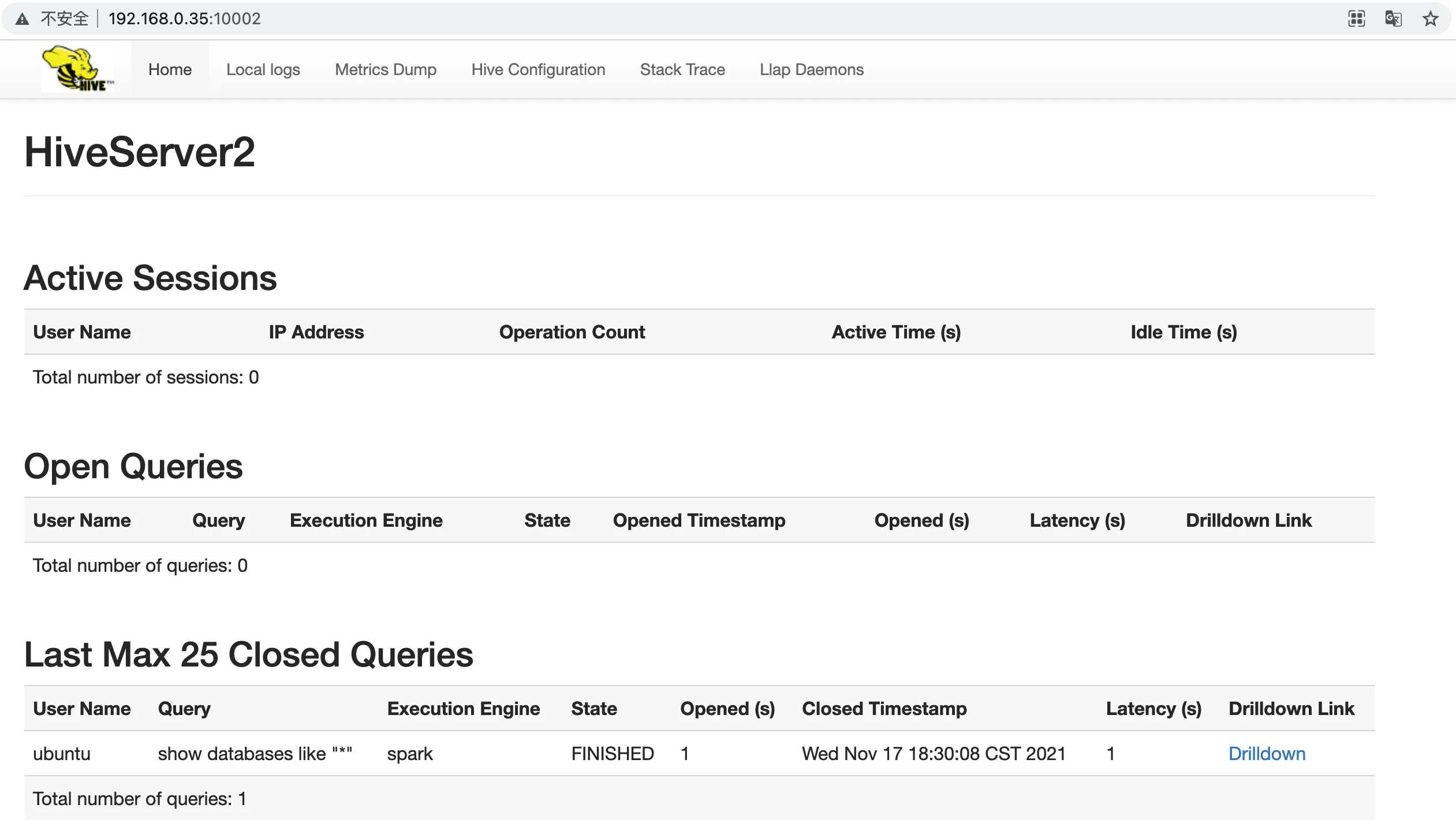
您可以通过访问 HiveServer2 WEB UI,查看运行记录。HiveServer2 WEB UI 展示的 sessions 和 queries 仅包含以 beeline 远程模式或其他方式提交到 HiveServer2 服务的任务。
在浏览器输入“http://<主节点 IP>:10002”,查看 HiveServer2 WEB UI。
| 说明 |
|---|
QingMR 1.3.0 及之后版本才支持通过此方式访问 HiveServer2 WEB UI。 |