常见问题
1. 作为新手,如何从一个最简单的例子入手?
2. App Ggent 是什么?如何安装 App Ggent?
下载云平台提供的 App Ggent:Linux 版本 或 Windows 版本。解压后运行 ./install.sh (Windows 下双击 install.bat)。
3. 如何创建 toml 和 tmpl 的模板文件?
可参考文档 创建模板文件。
4. 什么是 Metadata 服务,如何查询 Metadata 上的值?
云平台 AppCenter 的 metadata service 是在 etcd 基础之上进行了二次开发,主要增加了 self 属性,即每个节点只能从该服务获取到自身相关的信息,如本机 IP、server ID 等,此项目已在 github 上开源。
在创建好一个集群后,登录到任意一个节点,查看文件 /etc/confd/confd.toml 里 nodes 这一行,这一行定义的是 metadata server 的 IP 地址,任取其中一个 IP,运行下面命令即可看到所有信息。由于同一 VPC 里所有集群的 /etc/confd/confd.toml 文件内容相同,因此登录任一节点查看即可。
curl http://[IP]/self或者直接访问
curl http://metadata/self具体配置请参考文档 Metadata 服务
5. 如何查看日志?
-
查看集群云服务器里的 confd 日志
-
启动时的日志文件:
/opt/qingcloud/app-agent/log/confd-onetime.log -
修改了 confd 相关的
.toml和.tmpl文件后,执行了service confd restart命令之后重新生成新的 confd 相关的日志文件:/opt/qingcloud/app-agent/log/confd.log
-
-
查看应用本身服务调用的日志
应用本身服务的初始化、启动、停止等指令,在 AppCenter 云应用开发平台上可以查到相关日志。
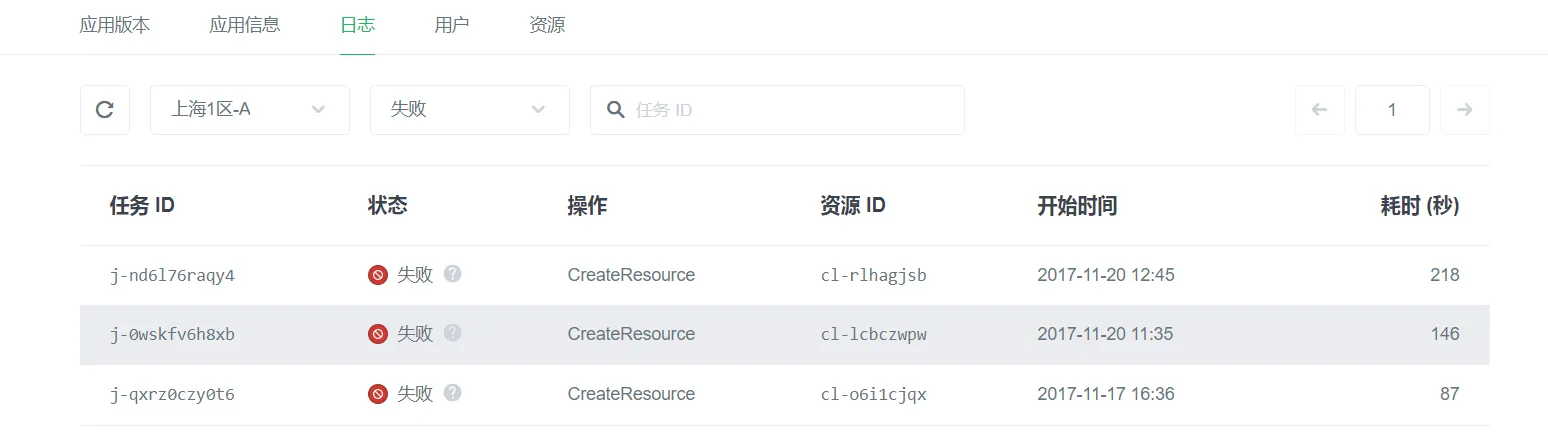
-
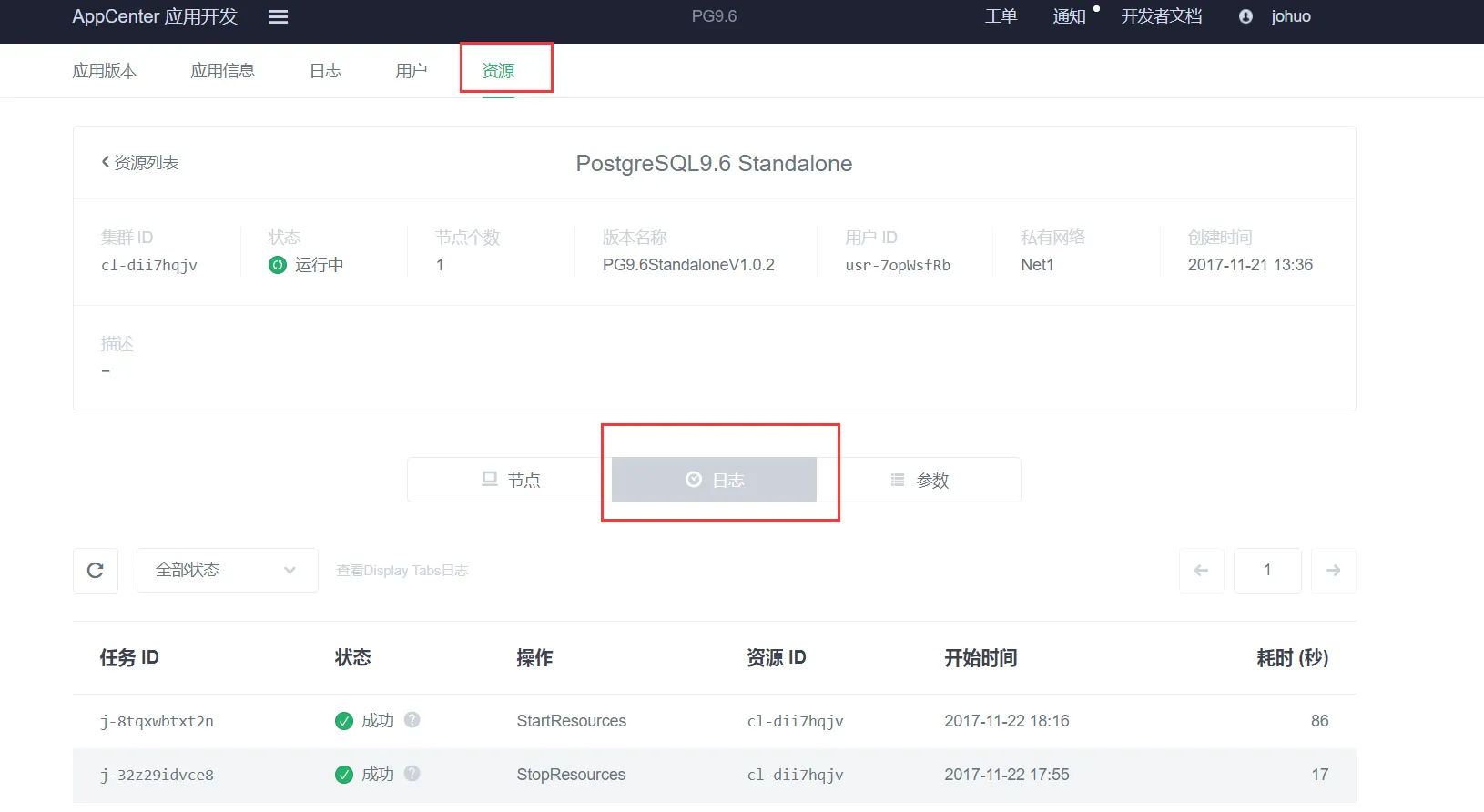
查看监控日志
监控日志主要是指用户开发的健康检查和监控命令调用的日志。在 AppCenter 云应用开发平台上可以查到相关日志。
6. 如何理解数据持久化和挂盘?如何配置?如何检查数据持久化是否配置成功?
持久化数据是指跟具体用户有关的数据,如 session、用户自己的数据如用户的数据库信息、用户设置的参数、日志等。 而应用程序,比如数据库应用程序本身不是持久化数据,因为它可以无差别的重复部署而不影响服务。
基于 AppCenter 开发的应用实例如果不配置挂载盘是不会保存用户需要持久化的数据的,在实例重启之后数据都会清空。 因此需要在 config 文件中配置挂盘,配置挂载盘之后,每次实例重新启动后会从该挂载盘的路径下读取用户持久化的数据。 具体参数配置如下所示:
# cluster.json.mustache 文件
"nodes": [
{
"role": "tomcat_nodes",
"container": {
"type": "kvm",
"zone": "pek3a",
"image": "img-h73eih5e"
},
"loadbalancer": {{cluster.tomcat_nodes.loadbalancer}},
"instance_class": {{cluster.tomcat_nodes.instance_class}},
"count": {{cluster.tomcat_nodes.count}},
"cpu": {{cluster.tomcat_nodes.cpu}},
"memory": {{cluster.tomcat_nodes.memory}},
"volume": {
"size": {{cluster.tomcat_nodes.volume_size}},
"mount_point": "/data", ***请注意这里!!!
"mount_options": "defaults,noatime",
"filesystem": "ext4"
}
}
]通常如果配置了数据持久化处理,在配置文件的 init 脚本中需要编写脚本,将应用的默认的数据路径下的数据复制到挂载盘下。 init 脚本在创建集群的时候调用,并且只在创建集群的时候调用一次。
# cluster.json.mustache 文件
"services": {
"init": {
"cmd": "systemctl restart rsyslog;mkdir -p /data/webapps;rsync -aqxP /opt/apache-tomcat-7.0.78/webapps/ /data/webapps"
}, ***请注意这里!!!
}如何检查数据持久化是否配置成功? 关闭集群,再启动集群,打开应用实例查看数据是否还在。
具体配置请参考文档 云应用开发模板规范 - 完整版。
7. 如何写健康检查的配置和脚本?
示例如下:
# cluster.json.mustache 文件
"health_check": {
"enable": true,
"interval_sec": 60,
"timeout_sec": 10,
"action_timeout_sec": 30,
"healthy_threshold": 3,
"unhealthy_threshold": 3,
"check_cmd": "/opt/myapp/bin/check.sh",
"action_cmd": "/opt/myapp/bin/action.sh"
}如果配置了此参数,在控制台上会展示各个节点的服务状态是否健康。

check_cmd 的内容为根据你的应用自己编写的脚本,appcenter 会根据 exit code 判断是否健康, exit code 为 0 则健康,非 0 则不健康。action_cmd 的内容为在服务不健康的情况下需要做的动作。
具体配置请参考文档 云应用开发模板规范 - 完整版。
8. 如何写监控数据的配置和脚本?
示例如下:
# cluster.json.mustache 文件
"monitor": {
"enable": true,
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pgmonitor.py",
"items": {
"connCnt": {
"unit": "",
"value_type": "int",
"statistics_type": "latest",
"scale_factor_when_display": 1
},
"commitCnt": {
"unit": "",
"value_type": "int",
"statistics_type": "latest",
"scale_factor_when_display": 1
}
},
"groups": {
"connCntGrp": ["connCnt"],
"commitCntGrp": ["commitCnt"]
},
"display": ["connCntGrp","commitCntGrp"],
"alarm": ["connCnt"]
}如果配置了此参数,在控制台上会展示各个节点的具体监控数据的值。 image::/images/cloud_service/appcenter/faq_monitor.webp[faq_monitor]
cmd的内容为根据你的应用自己编写的脚本,其返回结果是特定格式的json。
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:monitor
9. 如何写自定义服务的脚本?
示例如下:
# cluster.json.mustache 文件
"services": {
"init": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pginit.sh"
},
"start": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pgstart.sh"
},
"restart": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pgrestart.sh"
},
"RebuildStandby": {
"type": "custom",
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pgrebuildstandby.sh",
"timeout": 86400
}
},如果配置了此参数,在控制台上会展示各个节点的具体监控数据的值。 image::/images/cloud_service/appcenter/faq_customservice.webp[faq_customservice]
cmd 的内容为根据你的应用自己编写的脚本,自定义服务的内容。
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:"type": "custom"
10. 如何设置应用自身的配置参数?
首先在 config.json 文件中定义定义用户在创建应用的时候需填入的参数信息,参数包括资源信息如 CPU、内存、节点数等, 还包括应用本身配置参数以及外面依赖集群信息等。 这些信息有集群级别的全局设置,也有基于角色节点级别的信息设置。 其次,定义好参数信息,在c luster.json.mustache 文件中可以引用这些变量。
示例(应用全局级别)如下:
# config.json 文件
{
"key": "env",
"description": "application configuration properties",
"type": "array",
"properties": [
{
"key": "DBname",
"label": "DBname",
"description": "DB name to create",
"type": "string",
"default": "cloud",
"required": "yes",
"changeable": false
},
{
"key": "max_connections",
"label": "max_connections",
"description": "Sets the maximum number of concurrent connections.",
"type": "integer",
"default": 256,
"min": 0,
"max": 65536,
"required": "no"
}
]
}# cluster.json.mustache 文件
"env": {
"DBname": {{env.DBname}},
"max_connections": {{env.max_connections}}
}同时定义好应用的配置参数,在 confd 的 .tmpl 文件中可以使用这些参数。例如:
max_connections= {{getv "/env/max_connections"}}也可以使用 shell 脚本在 metadata server 上获取改值。
curl http://metadata/self/cluster/endpoints/reserved_ips/vip/value如果配置了此参数,在控制台集群列表的配置参数tab页可以查看具体配置信息。
image::/images/cloud_service/appcenter/faq_params.webp[faq_params]
角色节点级别的示例和具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:env
11. 用户输入参数如何做校验,如何支持正则表达式?
示例如下:
# config.json 文件
{
"key": "env",
"description": "Tomcat cluster service properties",
"type": "array",
"properties": [
{
"key": "tomcat_user",
"label": "User name to access Tomcat manager GUI",
"description": "User name to access Tomcat manager GUI, avoid to set it as 'tomcat' because it's already predefined with role 'manager_script'",
"type": "string",
"default": "qingAdmin",
"pattern": "^(?!.*?[tT][oO][mM][cC][aA][tT]).*$",
"required": "yes"
}
]
}如果配置了此参数,输入非法数据,在提交创建应用的时候会提示错误信息。 image::/images/cloud_service/appcenter/faq_pattern.webp[faq_pattern]
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:pattern
12. 如何展示节点的其他信息?
示例如下:
# cluster.json.mustache 文件
"display_tabs": {
"node_details": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pgnodedetails.sh",
"timeout": 10,
"description": ""
}
}如果配置了此参数,在控制台集群列表会多出一个tab页可以查看具体配置信息。 image::/images/cloud_service/appcenter/faq_nodedetails.webp[faq_nodedetails] cmd内容为采集的数据需执行的命令,必填项。 采集的数据以 JSON Object 的方式输出,例如:
# cluster.json.mustache 文件
{
"labels": ["节点ID","节点IP", "角色"],
"data": [
["cln-ydozfe18","192.168.100.2", "Master"],
["cln-fq788j27","192.168.100.6", "Standby"]
]
}返回结果会以表格的形式展示在集群详情页自定义标题的tab页下,其中 "labels" 和 "data" 是固定key。 labels 表示表格第一行的标题,是个 list,最多可定义5列; data标示表格里面每行数据,要求data是个list,list下是多个子list,最多255个。 其中每个子list标示一行数据,元素个数需和labels中一致。
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:display_tabs
13. 如何开放VNC给用户,允许用户访问节点?
示例如下:
# cluster.json.mustache 文件
{
"role": "log_node",
"container": {
"type": "kvm",
"zone": "pek3a",
"image": "img-b5urfv9t"
},
"instance_class": {{cluster.log_node.instance_class}},
"user_access": true, ***请注意这里!!!
"count": 1,
"cpu": {{cluster.log_node.cpu}}
}如果配置了此参数,在控制台上集群的节点列表下会有一个 VNC 的小图标,点击该图标可以登录该节点。
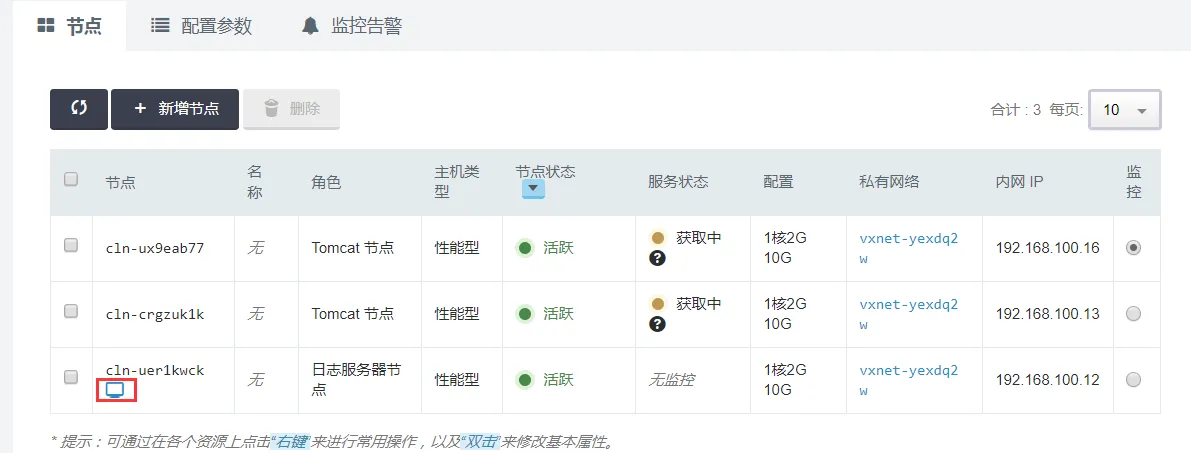
同时,在 AppCenter应用开发平台搜索找到你需要的应用,打开资源 tab 页,右侧有一个 VNC 小图标。
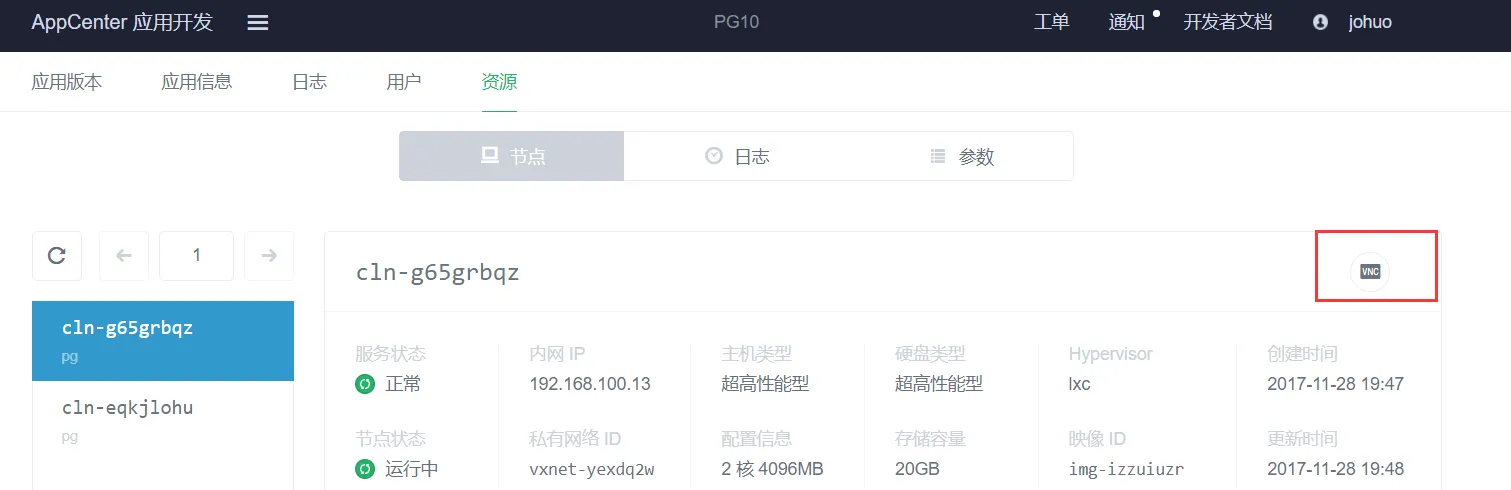
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:user_access
14. 如何备份?
backup_policy 定义应用的备份策略,支持 "device" 和 "custom" 两种类型。 "device" 表示对节点的挂盘做 snapshot;"custom" 则是使用自定义的备份命令进行备份操作,比如备份到某个目录,或拷贝到某个节点。非必填项
示例如下:
# cluster.json.mustache 文件
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"vxnet": {{cluster.vxnet}},
"backup_policy": "device", ***请注意这里!!!
}注意,如果设置了备份策略参数的话,必须将 service 下的 backup 命令写上,否则该参数不会生效。 示例如下:
# cluster.json.mustache 文件
"services": {
"init": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pginit.sh"
},
"backup": { ***请注意这里!!!
"cmd": "echo `date '+%Y-%m-%d %H:%M:%S'`':Info: Backup by Appcenter interface!' >>/data/pgsql/main/pg_log/pgscripts.log",
"timeout": 86400
},
"restore": {
"cmd": "echo `date '+%Y-%m-%d %H:%M:%S'`':Info: Backup by Appcenter interface!' >>/data/pgsql/main/pg_log/pgscripts.log",
"timeout": 86400
}
}如果配置了此参数,在控制台上集群右键会出现创建备份的菜单。
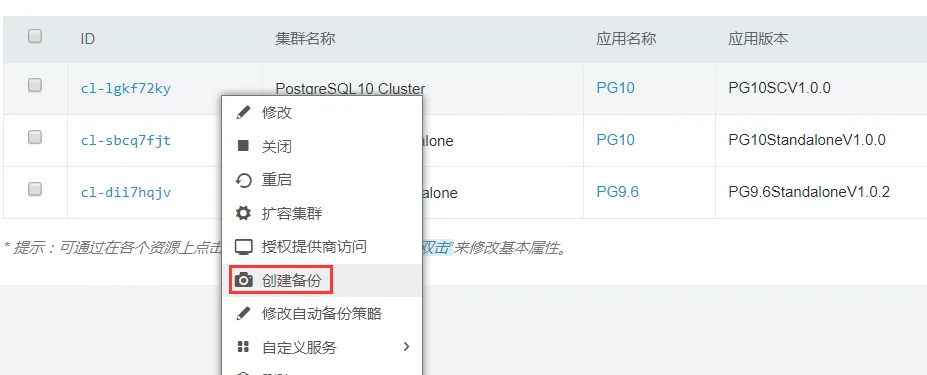
以上示例是基于device类型的备份策略,对于custom类型类似,但是需要注意如下几点:
-
"backup_policy": "custom",
-
"backup": cmd 参数会默认传入一个 snapshot id 作为参数,在 cmd 脚本可以获取到这个参数。 例如:执行的时候是
sh /opt/yourbackup.sh '{"snapshot_id": "s-12345678"}' 开发者可以解析后在 cmd 命令写成处理成cp /opt/data.txt /data/s-12345678 -
"restore": restore 操作的时候类似。cmd 参数会默认传入一个 snapshot id 作为参数,在 cmd 脚本可以获取到这个参数。 例如:执行的时候是
sh /opt/yourrestore.sh '{"snapshot_id": "s-12345678"}'开发者可以解析后在 cmd 命令写成处理成cp /data/s-12345678 /opt/data.txt
注意:restore 操作是在恢复的新集群上进行操作的。
incremental_backup_supported 定义应用是否支持增量备份。 备份分为全量备份和增量备份,全量备份每次创建新的备份链,而增量备份会在原有备份链上基于上一个备份点创建新的备份点,删除备份链上某一备份点后, 其后的所有备份点都会被相应删除。默认值为 false 表示只支持全量备份,非必填项。
示例如下:
# cluster.json.mustache 文件
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"upgrade_policy": ["appv-djgirq3p","appv-gr2vm9ee","appv-qmxgxyc1","appv-7tb3ldwl","appv-6vsdo968","appv-ng9ai35b","appv-f3stol95"],
"vxnet": {{cluster.vxnet}},
"backup_policy": "device",
"incremental_backup_supported": true,***请注意这里!!!
"nodes": [{
"role": "pg",
"container": {
"type": "lxc",
"image": "img-nkp0orrc",
"zone": "sh1a"
}
}]
}具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:backup_policy、backup、incremental_backup_supported
15. 如何升级,如何支持应用的大版本升级?
云应用支持的升级的原理是,用新的版本的镜像去驱动挂载盘下应用的数据,因此如果应用本身的版本没有变化或者只是小版本升级, 可以直接通过升级参数配置进行无缝升级。 示例如下:
# cluster.json.mustache 文件
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"vxnet": {{cluster.vxnet}},
"upgrade_policy": ["appv-djgirq3p"]
}同时,如果在升级的同时要做一些其他的任务,可以在 service 的 upgrade 脚本里编写自己的内容。示例如下:
# cluster.json.mustache 文件
"services": {
"init": {
"cmd": "/usr/lib/postgresql/9.6/bin/scripts/pginit.sh"
},
"upgrade": { ***请注意这里!!!
"cmd": "/opt/myapp/sbin/upgrade.sh"
}
}如果配置了此参数,在控制台上原来旧的版本的集群列表集群右侧会出现一个向上的升级箭头,关闭旧的集群,点击该图标就可以直接升级到最新的版本。 请注意 upgrade 脚本是在新的应用的集群上运行的。
对于应用的大版本升级的问题,例如 PostgreSQL9.6 和 PostgreSQL10,如果直接采用上面的方法是不可用的, 因为对于新版本的应用(PostgreSQL10)是无法驱动挂载盘下的旧版本(PostgreSQL9.6)格式的数据, 需要对挂载盘下的数据做转换才可以以升级后的新版本的应用读取数据。 因此,我们建议有以下2种方式进行升级处理。
-
新版本不直接支持从旧版本无缝升级到新版本,用户创建好新版本后,自己通过工具将数据从旧版本导入到新版本的集群中去。
-
新版本直接支持从旧版本无缝升级到新版本,在新版本的镜像中同时安装新旧2个版本,在 upgrade 的 cmd 编写脚本,
-
将数据从旧版本转换成新版本可直接读取的文件格式。
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:upgrade_policy、upgrade
16. 如何设置集群的 VIP?
示例如下:
# cluster.json.mustache 文件
"reserved_ips": {
"vip": {
"value": ""
}
}如果配置了此参数,在控制台上集群信息左侧会出现 VIP 的具体信息。

具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:reserved_ips
17. 如何支持用户下载和查看应用的日志?
对于这个需求,解决的办法可以有多种方式。
-
应用自身提供的 web 页面的 log 查看方式。
-
若应用本身不提供 web log,可以开放 ftp 权限给用户去应用的日志路径下查看日志。
-
采用第三方日志收集工具 rsyslog,logstash 等日志收集到日志节点,允许用户登录该节点查看日志。
-
其他方式。
18. 如何语言国际化?
如果您想要适应不同的语言,需要在提交的应用中包含一个 locale 文件夹,并添加对应语言的翻译文件,如:
-
locale/en.json 英文翻译文件
-
locale/zh-cn.json 中文翻译文件
示例如下:
# locale/zh-cn.json 文件
{
"Master": "主节点",
"Slave": "从节点",
"CPU": "CPU"
}config.json 定义用户在管理控制台部署应用时需要填写的表单。
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:国际化
19. 应用实例调用的脚本中环境变量在创建应用实例后变得不可用的问题?
如果我们在制作镜像的时候设置了一些环境变量,并在一些脚本文件中直接使用这些环境变量是没有问题的, 但在使用这个 image 实例化应用之后,这些环境变量会不可用。 因此建议大家在编写脚本的时候重新再 export 一下环境变量,或者 source 一下环境变量的文件。 例如 export PGDATA=/data/pgsql/main 或者 source /etc/profile
20. 如何配置依赖其他集群的服务?
示例如下:
# cluster.json.mustache 文件
"links": {
"redis_service": {{cluster.redis_service}},
"mysql_service": {{cluster.mysql_service}}
}# config.json 文件
{
"key": "redis_service",
"label": "Redis",
"description": " ",
"type": "service",
"tag": ["Redis","redis" ],
"limits": {"app-zydumbxo": ["appv-q1uwklp7"]},
"default": "",
"required": "no"
},
{
"key": "mysql_service",
"label": "MySql",
"description": " ",
"type": "service",
"tag": ["MySql","mysql"],
"limits": {"app-00r26u27": []},
"default": "",
"required": "no"
}其中 limits 参数的值为 app-id: [app-version]。若 version 列表为空,表示该应用所有版本均可支持。 如果配置了此参数,在控制台上新建集群的时候会出现当前实例所在的私网下存在的所依赖的服务。
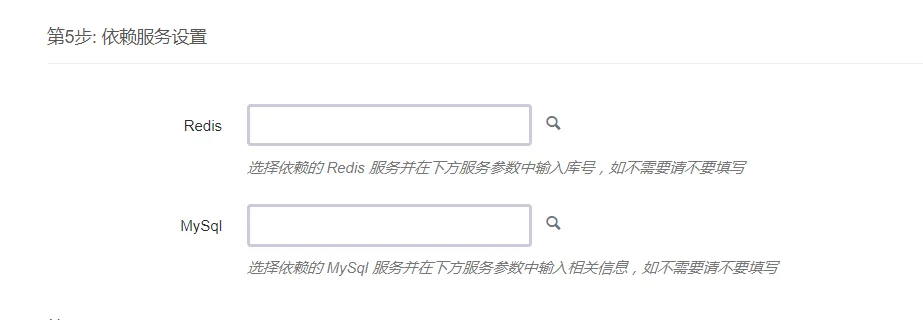
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:links、limits
21. 执行操作失败时如何展示给用户错误提示?
-
制作 image 时,规划好 cmd 在不同出错情况下 exit code 值。
-
配置文件 locale/zh-cn.json 中定义:
{ "err_code1": "禁止同时删除多个从节点" } -
配置文件 locale/en.json 中定义:
{ "err_code1": "Permission denied to delete multiple slave nodes" }
在执行操作 cmd 时,遇到 exit code 是 1 的情况时,会给用户如下提示:
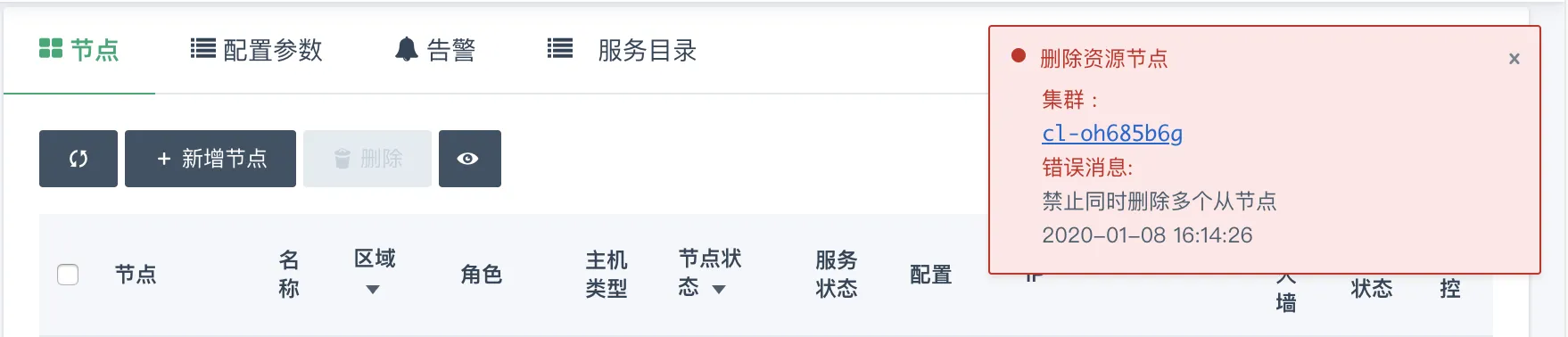
22. 如何配置横向扩容?
示例如下:
# cluster.json.mustache 文件
"nodes": [
{
"role": "tomcat_nodes",
"container": {"type": "kvm","zone": "pek3a","image": "img-h73eih5e"},
"loadbalancer": {{cluster.tomcat_nodes.loadbalancer}},
"instance_class": {{cluster.tomcat_nodes.instance_class}},
"count": {{cluster.tomcat_nodes.count}},
"cpu": {{cluster.tomcat_nodes.cpu}},
"memory": {{cluster.tomcat_nodes.memory}},
"advanced_actions": ["scale_horizontal"] ***请注意这里!!!
}
]同时,如果在升级的同时要做一些其他的任务,可以在 service 的 upgrade 脚本里编写自己的内容。示例如下:
# cluster.json.mustache 文件
"services": {
"scale_out": {
"pre_check": "/opt/myapp/sbin/scale-out-pre-check.sh",
"cmd": "/opt/myapp/sbin/scale-out.sh"
},
"scale_in": {
"pre_check": "/opt/myapp/sbin/scale-in-pre-check.sh",
"cmd": "/opt/myapp/sbin/scale-in.sh",
"timeout": 86400
},
}如果配置了此参数,在控制台上集群节点列表上会出现新增节点的按钮。
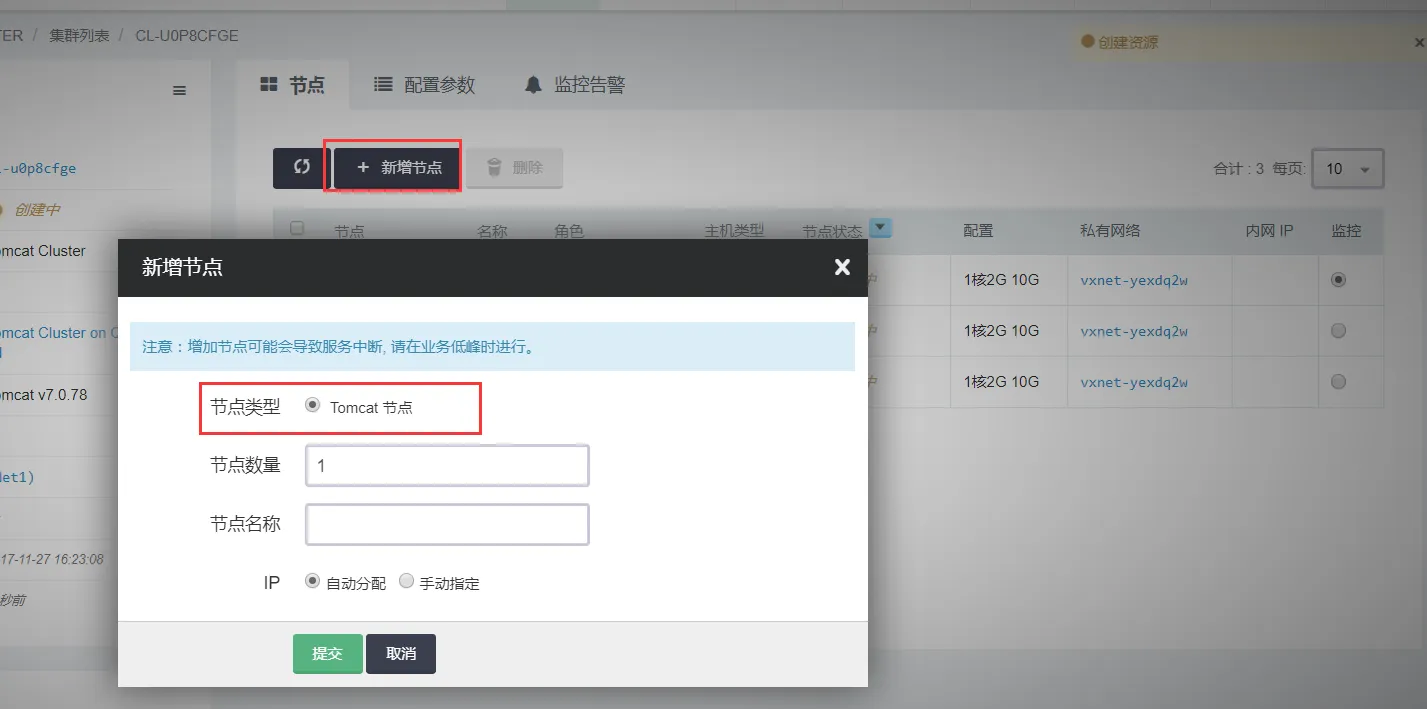
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:advanced_actions、scale_horizontal、scale_out、scale_in
23. 如何支持集群切换私网网络?
变换网络 (change_vxnet) 如果您的应用支持切换网络可以加上 change_vxnet。
# cluster.json.mustache 文件
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"vxnet": {{cluster.vxnet}},
"backup_policy": "device",
"advanced_actions": ["change_vxnet"]
}如果配置了此参数,在控制台上集群列表选中集群右键会出现切换私有网络菜单。
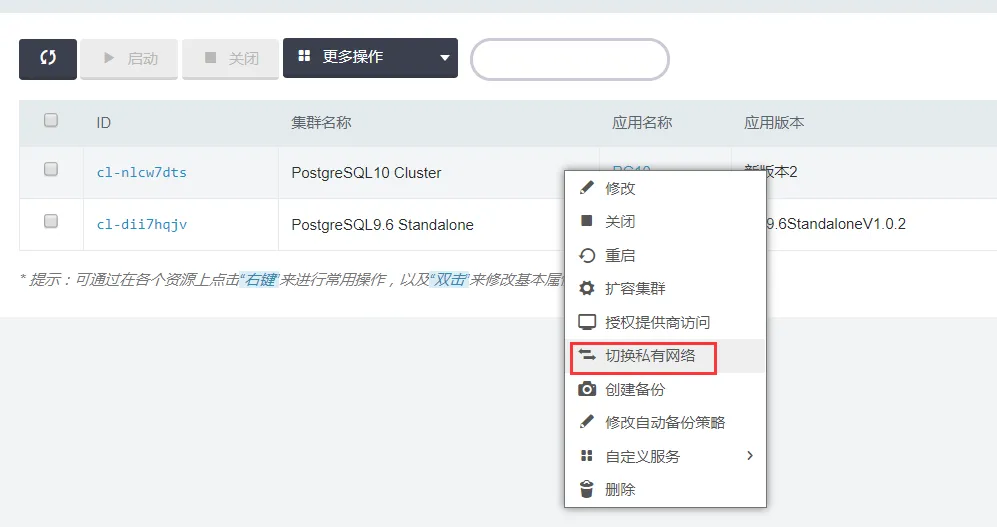
具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:advanced_actions、change_vxnet
24. 如何将角色的某个节点直接绑定公网 IP?
绑定公网 IP (associate_eip) 如果该角色的节点需要直接绑定公网IP可以加上 associate_eip,
绑定公网 IP 会给这个集群绑定默认集群防火墙, 其他集群如果需要访问这个集群请在集群防火墙中添加对应放行规则。
# cluster.json.mustache 文件
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"vxnet": {{cluster.vxnet}},
"backup_policy": "device",
"advanced_actions": ["associate_eip"]
}具体配置请参考文档 云应用开发模板规范 - 完整版。
关键字:advanced_actions、associate_eip
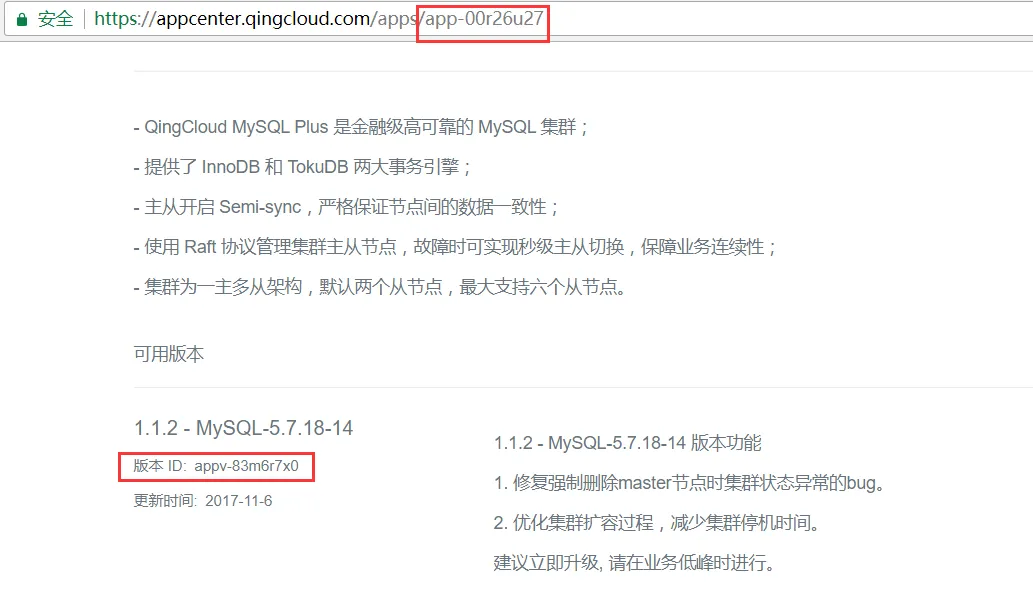
25. 如何获取依赖其他集群的服务的 AppID 和 AppVersionID?
在配置依赖服务的时候,配置参数需要知道所依赖的服务的 AppID 和 AppVersionID。 在 AppCenter 应用开发平台搜索找到你需要的应用,打开可以看到相关信息。
26. 能否提供一些 confd templates(即 tmpl 文件)的使用例子?
示例1:
获取集群中所有节点的 ip 地址,range 循环的用法
{{range $dir := lsdir "/hosts"}}
{{$sid := printf "/hosts/%s/sid" $dir}}
{{$ip := printf "/hosts/%s/ip" $dir}}
server.{{getv $sid}}={{getv $ip}}:2888:3888
{{end}}confd service restart 刷新后的信息为
server.1=192.168.100.2:2888:3888
server.2=192.168.100.3:2888:3888
server.3=192.168.100.4:2888:3888示例 2:
定义一个变量并使用这个变量
{{$tomcat_user :=getv "/env/tomcat_user"}}
{{$tomcat_pwd :=getv "/env/tomcat_pwd"}}
<user username="{{$tomcat_user}}" password="{{$tomcat_pwd}}" roles="manager-gui" />
<user username="tomcat" password="{{$tomcat_pwd}}" roles="standard,manager-script,manager-jmx,manager-status" />示例3: 获取一个key的值
max_connections= {{getv "/env/max_connections"}}示例4: 对算术的支持 div
{{$shared_buffers := div (getv "/host/memory") 4}}示例5: if else 的用法
{{$SyncStreamRepl := getv "/env/SyncStreamRepl"}}
{{if eq $SyncStreamRepl "No" }}
synchronous_standby_names = ''
{{else}}
synchronous_standby_names = '*'
{{end}}示例6: split的用法
{{ $replicaIPs := split (getv "/host/ip") "." }}
{{index $replicaIPs 0}}.{{index $replicaIPs 1}}.{{index $replicaIPs 2}}.0/24更多 template 的函数使用示例请参考yunify/confd
27. confd 日志显示 key 找不到的错误信息
经常会在 confd 的日志文件中看到类似于如下错误信息,通常情况是在 toml 文件没 watch 该 key,或者该 key 不存在,
可以通过 curl http://metadata/self 查看。
2016-10-11T13:54:41+08:00 i-lvn35udh confd[1531]: ERROR template: index.html.tmpl:2:7: executing "index.html.tmpl" at <getv "/self/host/sid...>: error calling getv: key does not exist: /self/host/sid28. 上传配置包时报错:配置验证失败,报[config.json] Not valid json错误?
需要检查 config.json 文本内容,是否有中文符号或其他不符合 json 格式的部分,可以通过在线工具验证合法性,比如 jsonlint。 同时配置包中文件不支持 "UTF-8 Unicode (with BOM) text" 文本格式,windows下的编辑器编辑文件默认是此格式也会报此错误, 可通过 "格式-> 以utf-8无BOM格式编码" 进行转换。
29. 我在测试的时候发现设置的服务价格没起作用,原因是什么?
自己测试自己的应用的时候是不收取服务费用的,一旦上线用户使用的时候会收取您设置的服务费用。
30. 节点的启动/停止命令执行出错,请确保命令写完整的全路径。
当定义的应用的启动/停止/监控命令执行有问题,例如 文件定义如下
"start":"your_script"服务日志如下
2017-04-13 12:14:19,318 ERROR Failed to execute the [cmd:your_script, id:JPwqtXY56Mp22t0RsqkDtQVu3hQLxxxx] in the node [cln-pwgxxxxx]请确认起停的命令要写全路径。例如
"start":"/bin/your_script"要保证脚本在任意路径下调用都可以成功返回。 例如在创建好的集群中,执行如下命令返回正常。
cd /tmp
/opt/yourscript.sh31. 使用 kvm 作为镜像模板时,应用创建资源失败
登录创建的节点发现文件系统变成只读,且日志如下:
2017-04-17 11:03:48,800 CRITICAL Mount volume [{'mount_point': '/data', 'mount_options': '', 'filesystem': 'ext4'}] on node [cln-bo73222b] failed请确保在制作镜像时正常关机,保证磁盘正常卸载。
32. 使用说明和服务条款的 Markdown 语法说明
-
支持标准的 Markdown 语法,同时你也可以直接使用 HTML 代码
-
Markdown 转换后的内容是没有样式,如果你想再添加样式,可以将下面的 HTML 代码添加到你输入的内容之前:
<link href="https://cdn.bootcss.com/foundation/6.3.1/css/foundation.min.css" rel="stylesheet">
在使用说明中,如果只输入一个网址,用户在查看使用说明时会直接跳转到该网址
33. 如果只想用云应用开发框架管理纯云服务器集群
可以不用装云平台提供的 App agent,以下是样例。
# config.json
{
"type": "array",
"properties": [{
"key": "cluster",
"description": "Sample cluster properties",
"type": "array",
"properties": [{
"key": "name",
"label": "name",
"description": "The name of the Sample service",
"type": "string",
"default": "Sample",
"required": "no"
}, {
"key": "description",
"label": "description",
"description": "The description of the Sample service",
"type": "string",
"default": "",
"required": "no"
}, {
"key": "vxnet",
"label": "VxNet",
"description": "Choose a vxnet to join",
"type": "string",
"default": "",
"required": "yes"
}, {
"key": "role_name1",
"label": "role_name1",
"description": "role-based role_name1 properties",
"type": "array",
"properties": [{
"key": "cpu",
"label": "CPU",
"description": "CPUs of each node",
"type": "integer",
"default": 1,
"range": [1, 2, 4, 8, 16],
"required": "yes"
}, {
"key": "memory",
"label": "Memory",
"description": "Memory of each node",
"type": "integer",
"default": 2048,
"range": [2048, 8192, 16384, 32768, 49152],
"required": "yes"
}, {
"key": "count",
"label": "Count",
"description": "Number of nodes for the cluster to create",
"type": "integer",
"default": 3,
"max": 100,
"min": 1,
"required": "yes"
}, {
"key": "volume_size",
"label": "Volume Size",
"description": "The volume size for each instance",
"type": "integer",
"default": 10,
"min": 10,
"max": 1000,
"step": 10,
"required": "yes"
}, {
"key": "instance_class",
"label": "resource type",
"description": "The instance type for the cluster to run, such as high performance, high performance plus",
"type": "integer",
"default": 0,
"range": [
0,
1
],
"required": "yes"
}]
}]
}]
}其中 img-hlhql5ea 是没有安装 app agent 的镜像,agent_installed 用来标识此 role 没有安装 agent
# cluster.json.mustache
{
"name": {{cluster.name}},
"description": {{cluster.description}},
"vxnet": {{cluster.vxnet}},
"nodes": [
{
"role": "role_name1",
"container": {
"type": "kvm",
"zone": "pek3a",
"image": "img-hlhql5ea"
},
"agent_installed": false,
"instance_class": {{cluster.role_name1.instance_class}},
"count": {{cluster.role_name1.count}},
"cpu": {{cluster.role_name1.cpu}},
"memory": {{cluster.role_name1.memory}},
"volume": {
"size": {{cluster.role_name1.volume_size}},
"mount_point": "/test_data",
"filesystem": "ext4"
}
}
]
}34. 如何使用环境变量里的 accesskey 类型数据?
如果需要用户提供 API 密钥并写入环境变量,可以使用数据类型 accesskey
示例如下:
# cluster.json.mustache 文件
{
"env": {
"access_key": {{env.access_key}}
}
}# config.json 文件
{
"key": "env",
"description": "application configuration properties",
"type": "array",
"properties": [{
"key": "access_key",
"label": "access_key_id",
"description": "access key ID",
"type": "accesskey",
"required": "yes"
}]
}通过如下方法获取用户 API 密钥及其私钥:
curl http://metadata/self/env/access_key/access_key_id
curl http://metadata/self/env/access_key/secret_access_key关键字:env、accesskey、metadata
35. 环境变量里如何支持层级联动关系?
{
"key": "env",
"description": "application configuration properties",
"type": "array",
"properties": [{
"key": "s3_type",
"label": "s3.type",
"description": "Type of s3 compatible object store",
"type": "string",
"default": "none",
"range": ["none","minio","QingStor"],
"required": "yes"
}, {
"key": "access_key",
"label": "access.key",
"description": "Access key used to access QingStor object store",
"type": "accesskey",
"dependencies":[
{"refkey":"s3_type","values":["QingStor"],"operator":"in"}
],
"required": "yes"
}, {
"key": "s3_access_key",
"label": "s3.access.key",
"description": "Access key used to access MinIO object store",
"type": "password",
"default": "AKIAIOSXODNN7EXAMPLE",
"pattern": "^.{20}$",
"changeable": true,
"dependencies":[
{"refkey":"s3_type","values":["minio"],"operator":"in"}
],
"required": "yes"
}, {
"key": "s3_secret_key",
"label": "s3.secret.key",
"description": "Secret key used to access MinIO object store",
"type": "password",
"default": "wJalrXUtqFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
"pattern": "^.{40}$",
"changeable": true,
"dependencies":[
{"refkey":"s3_type","values":["minio"],"operator":"in"}
],
"required": "yes"
}
]
}当 s3_type 值为 none 时,access_key、s3_access_key 和 s3_secret_key 都不显示

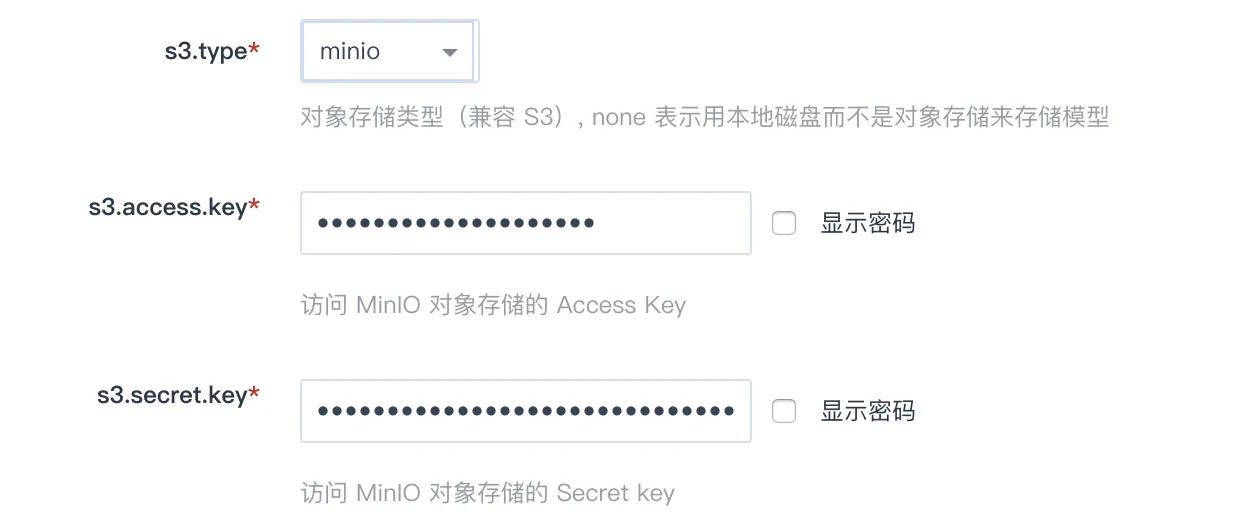
当 s3_type 值为 minio 时,s3_access_key 和 s3_secret_key 显示,access_key 不显示
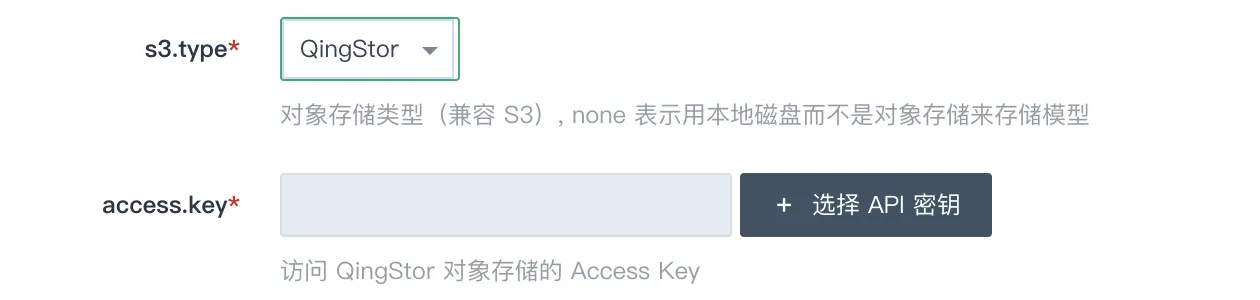
当 s3_type 值为 QingStor 时,access_key 显示,s3_access_key 和 s3_secret_key 都不显示
36. 如何定义原地升级方式?
-
cluster.json.mustache 的 upgrading_policy 定义为 in-place-parallel 或 in-place-sequential,同时定义 in-place-upgrade-nodes 信息:
{ "upgrading_policy": "in-place-parallel", "in-place-upgrade-nodes": [{ "container": { "snapshot": "ss-skhdp1m1", "zone": "pek3" }, "copy": [{ "mount_role": "master", "mount_point": "/data1", "mount_options": "defaults,noatime", "filesystem": "ext4", "source": "/data1/upgrade1/bin", "destination": "/data/bin" }, { "mount_role": "slave", "mount_point": "/data2", "mount_options": "defaults,noatime", "filesystem": "ext4", "source": "/data2/upgrade1/bin", "destination": "/data/bin" } ] }] }参数 - - 描述 upgrading_policy
-
-
定义版本升级的模式,支持 in-place-parallel 或 in-place-sequential
in-place-upgrade-nodes
-
-
原地升级时,需要使用的备份以及拷贝操作信息,定义在里面。
-
container
-
备份信息,必填项。
-
-
snapshot
备份 ID。
-
-
zone
备份制作时所属区域。
-
copy
-
定义由备份恢复的硬盘,原地升级时拷贝操作相关信息。
-
-
mount_role
将备份恢复的硬盘,挂载到哪个角色节点上,该角色所有节点都会挂载硬盘。
-
-
mount_point
备份恢复的硬盘的挂载路径,比如 /data1。
-
-
mount_options
描述数据盘的挂接方式,默认值 ext4 是 defaults,noatime,xfs 是 rw,noatime,inode64,allocsize=16m。
-
-
filesystem
备份恢复的硬盘的文件系统类型。目前支持 ext4 和 xfs,默认是 ext4。
-
-
source
需要拷贝数据的源目录,也就是 mount_point 下的目录。
-
-
source
需要拷贝数据的目标目录。拷贝失败时会删除该目录,拷贝成功不做任何处理,建议该目录使用一个临时目录,后面开发者可以在 services 下 upgrade 操作定义后续的操作。
-
由硬盘制作备份时,需要制作 qcow2 格式的全量备份。
./create-snapshots -r vol-pisotyhp -F 1 -m qcow2
37. 升级操作时如何给用户弹出提示?
-
配置文件 locale/zh-cn.json 中定义:
{ "notice_when_upgrade": "此版本包含不兼容 Kafka 1.x 版本的改动,可能会导致业务代码异常退出并无法回退!为避免损失,强烈建议先创建一个新集群进行验证,确保可以工作以后再进行升级操作。Kafka 2.3 版本说明请查看官方文档:https://kafka.apache.org/documentation/" } -
配置文件 locale/en.json 中定义:
{ "notice_when_upgrade": "The new version app may need refit your kafka consumer code! Make sure you are using the new config!!!" }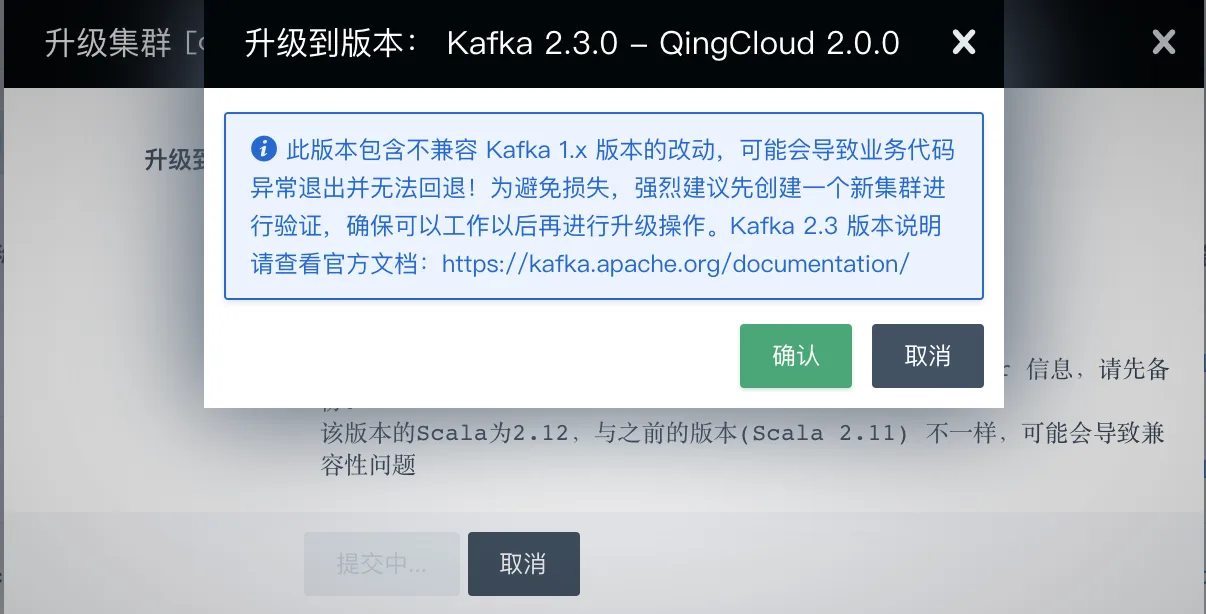
38. 串行纵向扩容或滚动升级时,如何按照一定顺序进行操作?
一些应用同一角色内多个节点之间地位不同,仍然会有主从关系。在纵向扩容或滚动升级时,希望优先操作从节点,最后操作主节点,以达到最少主从切换的目的。 同一角色内多个节点之间的身份,只有应用实例自己知道,可以通过定义 get_nodes_order 的方式来实现这个目的:
"services": {
"get_nodes_order": {
"event": ["upgrade", "rollback", "scale_vertical"],
"cmd": "/opt/myapp/bin/get-nodes-order.sh"
}
}其中 event 的可选值为:upgrade, rollback, scale_vertical。表示在定义的生命周期到来时,使用 get_nodes_order 中 cmd 的执行结果作为该生命周期节点的操作顺序。
{event: xx} 会作为 cmd 的 $1 传入。
例:
集群 cl-12345678 有 3 个节点,分别是:cln-11111111, cln-22222222, cln-33333333。
/opt/myapp/bin/get-nodes-order.sh 的返回结果为:cln-33333333,cln-22222222,cln-11111111,逗号分隔的节点 id 列表。
则在滚动升级和串行纵向扩容时,按照 cln-33333333,cln-22222222,cln-11111111 的节点顺序,执行这个生命周期下的操作。