基于 minGPT 创建 PyTorch 分布式训练任务
环境准备
-
获取示例代码。
-
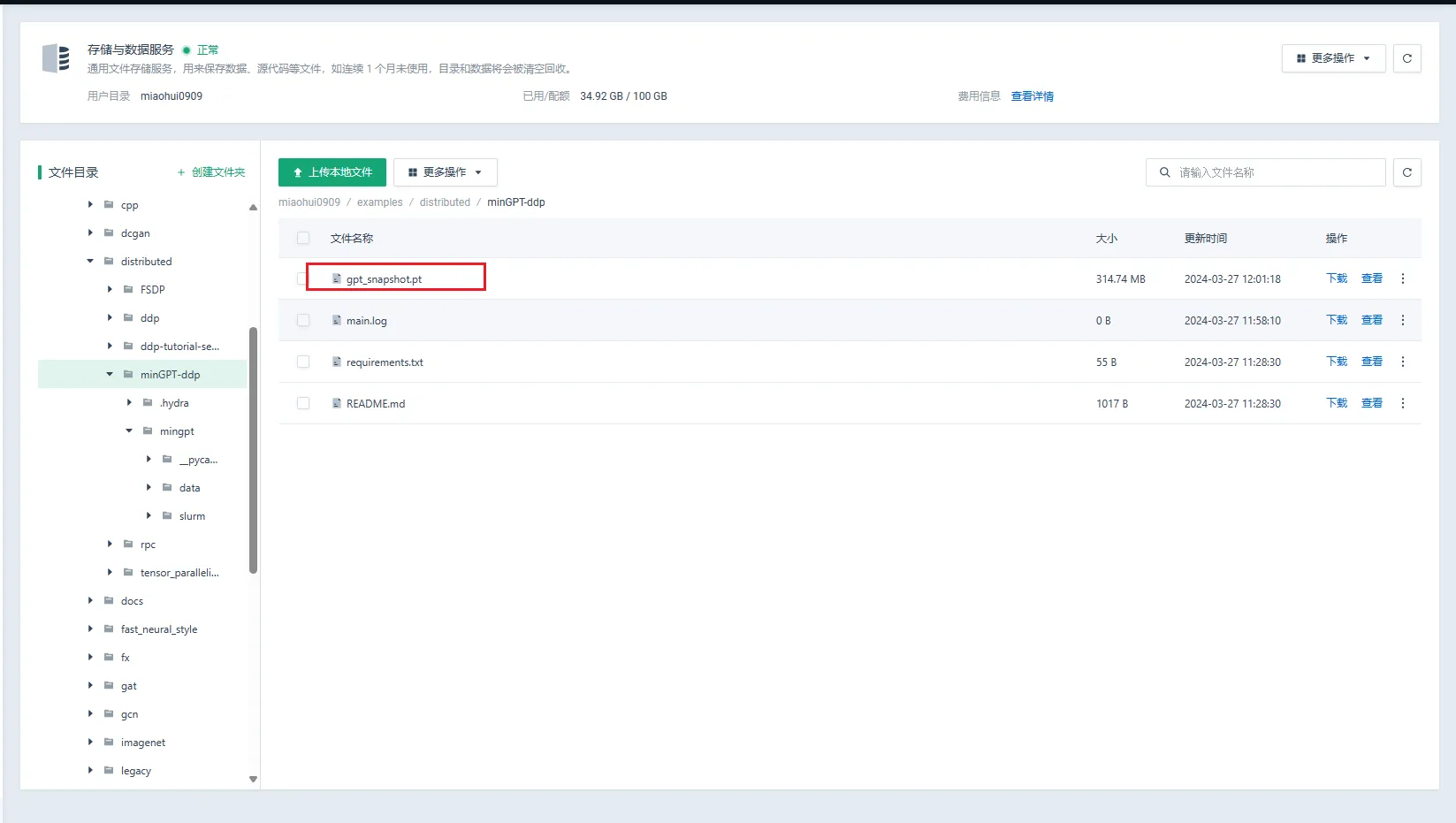
创建文件存储,并将上一步获取的示例代码上传至指定文件目录下。
-
注意 -
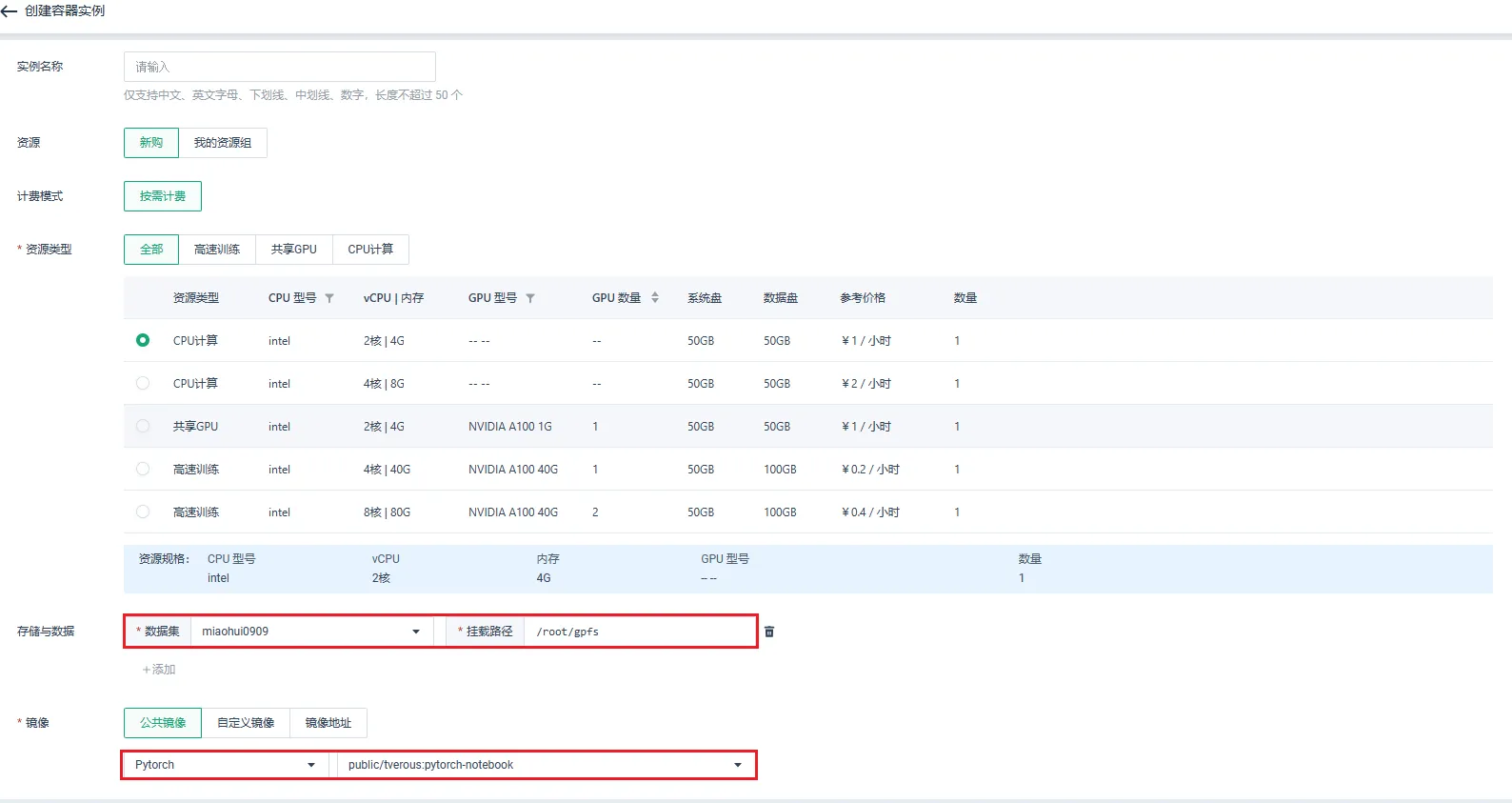
容器实例的存储与数据的数据集必须选择上一步中上传有示例代码的用户目录。
-
容器实例的镜像必须选择 Pytorch。
-
-
使用 jupyter 登录容器实例,在 Terminal 内执行如下命令,安装环境依赖。
pip install -r /root/epfs/examples/distributed/minGPT-ddp/requirements.txt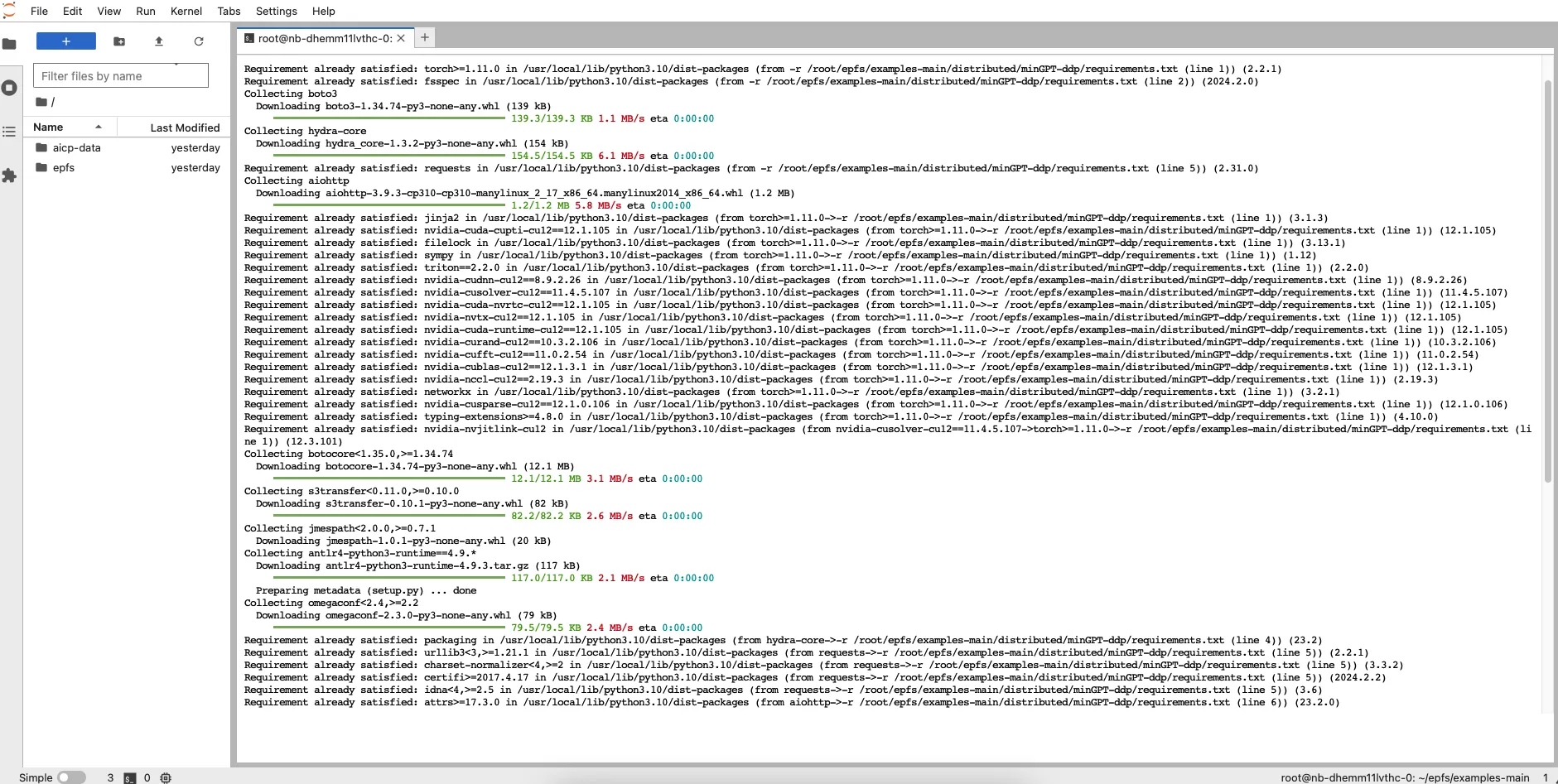
-
将安装了环境依赖的容器实例,保存为自定义镜像。
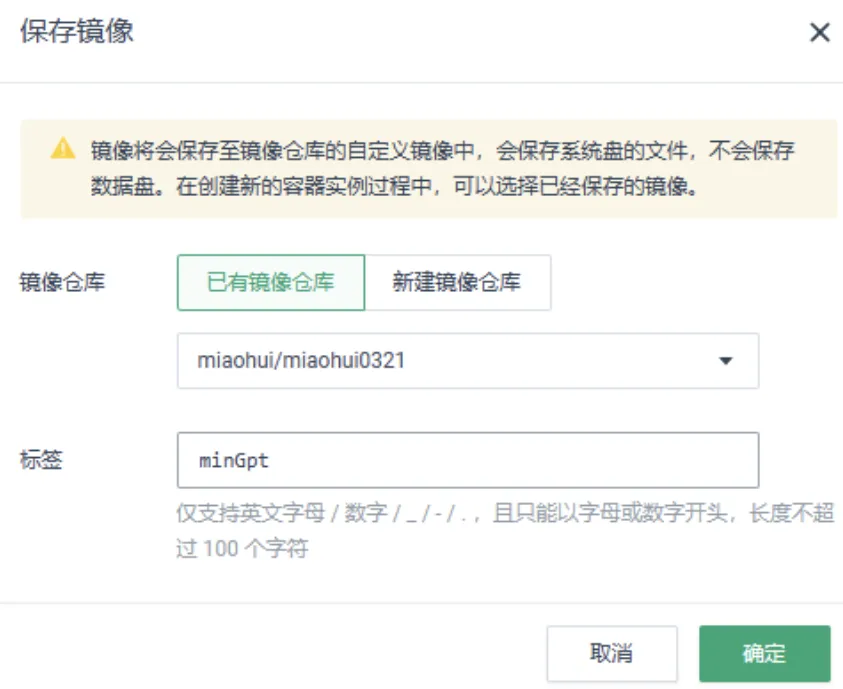
提交训练任务
-
完成环境准备相关操作。
-
在创建分布式训练任务页面,按照以下要求配置各项参数。
说明 如果 PyTorch 作业以分布式运行, 其中 PyTorch 所需要的分布式参数将会以环境变量的形式自动注入到运行的环境中。
-
任务名称:用户自定义即可,输入简要任务说明。
-
镜像:选择自定义镜像,并选择环境准备中自制镜像。
-
存储与数据:选择环境准备中上传有示例代码的用户目录。
-
启动命令:训练任务的启动命令,根据环境准备中上传的数据,则该示例的启动命令为:
torchrun /root/epfs/examples/distributed/minGPT-ddp/mingpt/main.py。 -
环境变量:用户根据实际情况指定相应的环境变量。
-
TensorBoard:如果结束后想使用平台的 Tensorboard, 请将日志写入环境变量
TENSORBOARD_LOG_PATH所指定的地址。 -
自动重试: 如果开启, 作业因为异常推出后会进行自动重试.
-
超时配置: 如果开启, 作业将会在运行指定事件后自动退出.
-
框架: 选择 Pytorch。
-
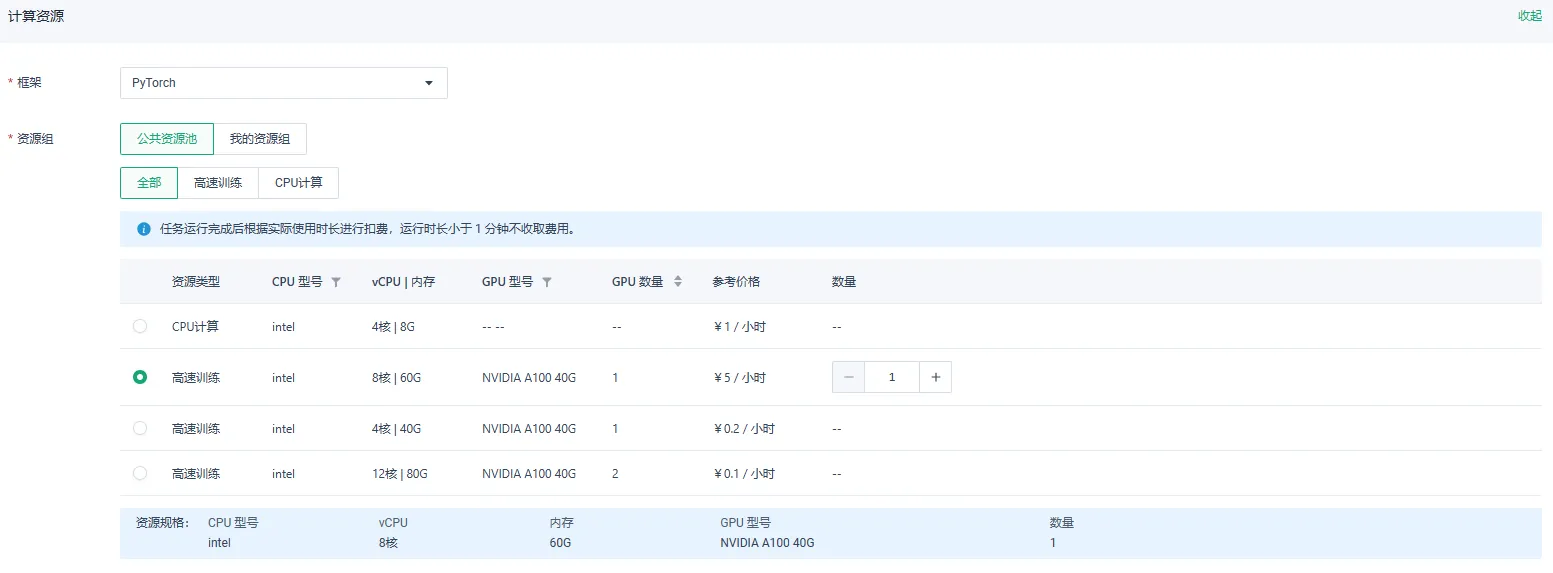
单节点单卡训练
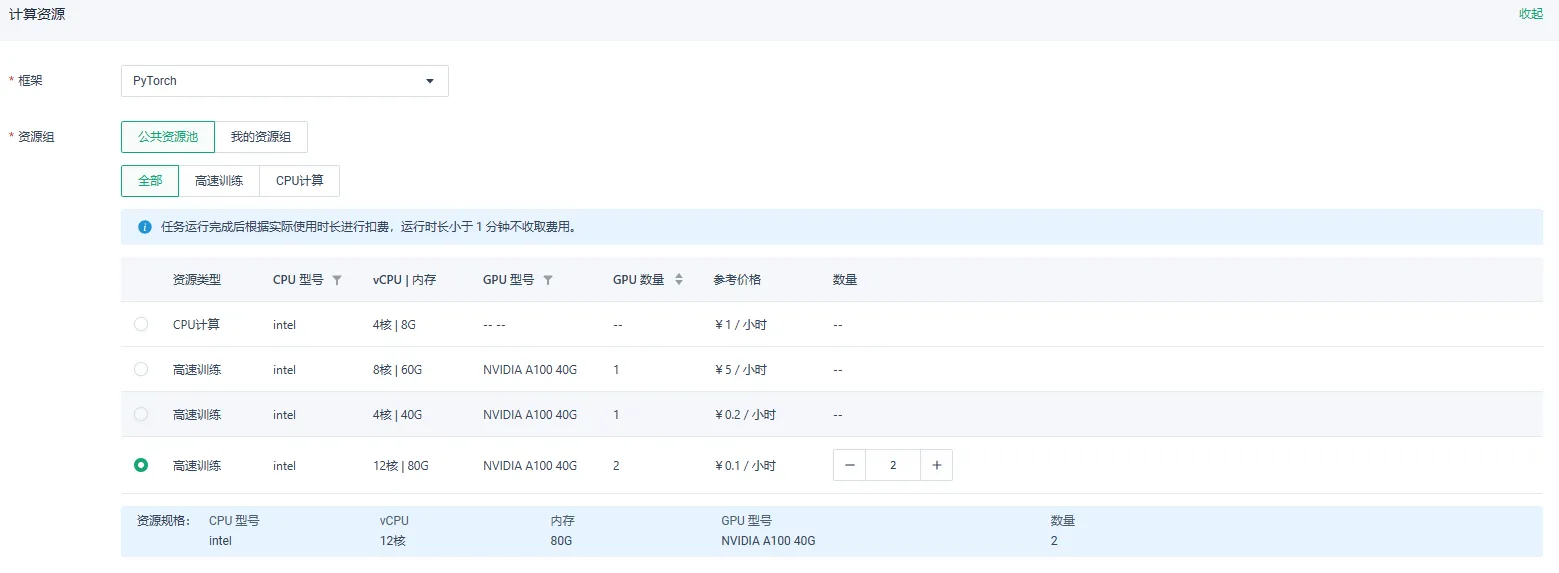
根据上述步骤配置完成相关参数,计算资源中的资源组选择公共资源池,并选择GPU 数量为 1 的资源类型,并设置数量为 1。 点击确定,即可提交单节点单卡训练。
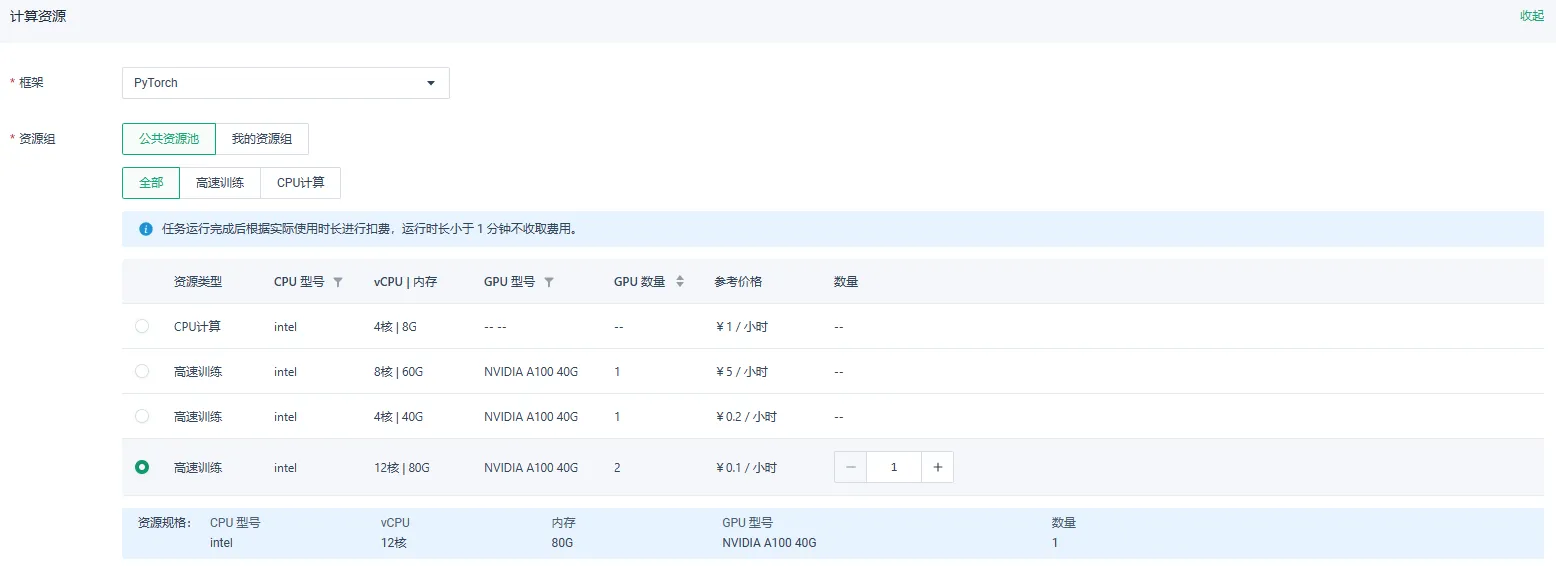
单节点多卡训练
根据上述步骤配置完成相关参数,计算资源中的资源组选择公共资源池,并选择GPU 数量大于 1 的资源类型,并设置数量为 1。 点击确定,即可提交单节点多卡训练。
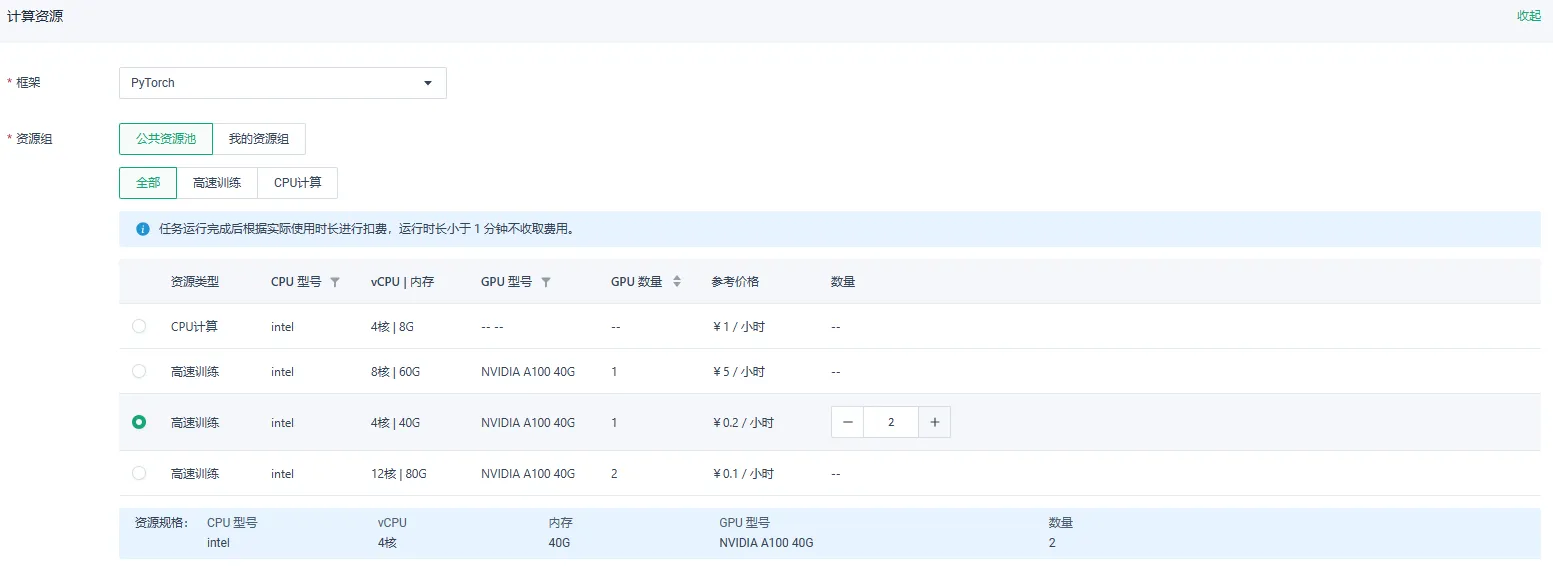
多节点单卡训练
根据上述步骤配置完成相关参数,计算资源中的资源组选择公共资源池,并选择GPU 数量为 1 的资源类型,并设置数量大于 1。 点击确定,即可提交多节点单卡训练。
多节点多卡训练
根据上述步骤配置完成相关参数,计算资源中的资源组选择公共资源池,并选择GPU 数量大于 1 的资源类型,并设置数量大于 1。 点击确定,即可提交多节点多卡训练。
查看结果
等待训练任务运行结束,查看任务详情。若训练过程中已将 Tensorboard 日志写入到环境变量TENSORBOARD_LOG_PATH 所指定的地址, 任务训练结束后可以点击 Tensorboard 按钮,打开 Tensorboard 查看训练过程。
查看输出模型
最后训练任务输出的 AI 模型,会保存到用户指定的路径中,可在存储与数据服务中查看。建议用户将相应模型保存到离线存储中方便后续使用。