基于 PyTorch 的 LLaMA 2 模型微调
LLaMA 是比较常用的开源模型,此最佳实践介绍如何在AI 智算平台基于 LLaMA 2 7B 的中文预训练模型(Atom-7B-Chat)使用提交分布式训练任务的方式进行模型微调。
操作步骤
-
登录QingCloud 管理控制台。
-
将获取到的训练模型和代码文件在本地进行解压后,采用 SFTP 方式上传至文件存储的指定目录下。
如下示例,已创建名称如
xxxx0002的用户目录,将训练模型和相应代码分别上传至/xxxx0002/Atom-7B-Chat和/xxxx0002/Llama-Chinese文件夹下。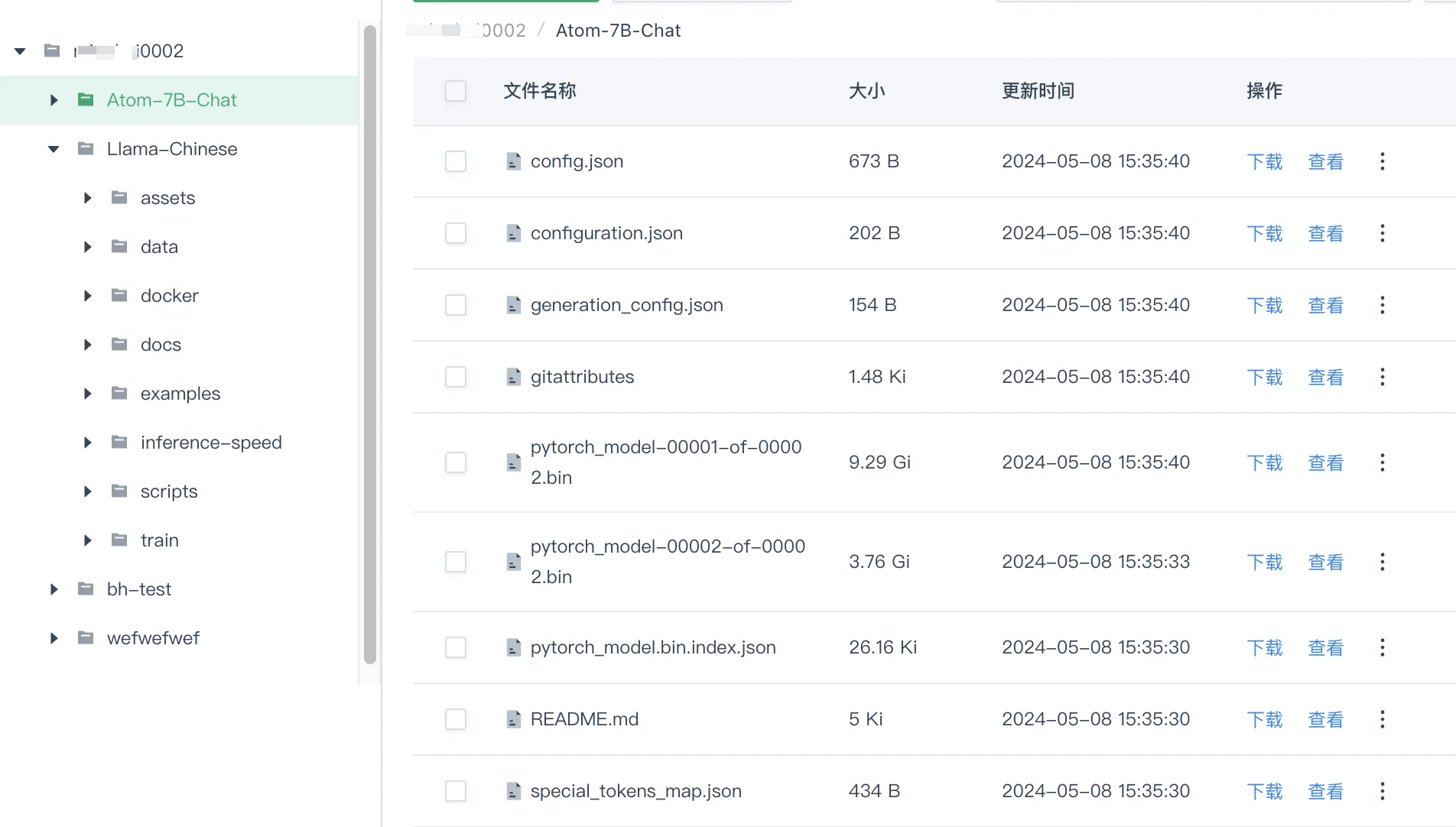
-
创建分布式训练任务,配置参数要求如下。
配置项 参数 说明 任务信息
任务名称
用户根据实际情况自定义即可。
镜像
本示例中选择
镜像地址,并输入正确的镜像地址(如sjz-dockerhub.qingcloud.com/public/llama2-train:pytorch-2.1.2-cuda12.1-cudnn8,其中sjz-dockerhub.qingcloud.com为镜像仓库地址)后,选择无密码以获取镜像。说明 各个可用区内的镜像仓库地址和私有镜像仓库密码需根据实际情况进行修改,用户可在平台左侧导航栏选择资源管理 > 镜像仓库 > 自定义镜像仓库,查看镜像镜像仓库地址和相应的账号密码。
存储与数据
选择上一步上传了代码文件的用户目录即可。
代码
此示例中无需再上传代码文件。
环境变量
此示例中无需设置。
启动命令
根据上一步上传的代码文件路径,此处应为:
bash /root/epfs/Llama-Chinese/train/sft/torchrun_finetune_lora.sh,其中脚本所在路径需根据实际情况进行修改。自动重试
选择
关闭即可。超时配置
选择
关闭即可。计算资源
框架
选择
Pytorch。资源组
选择
公共资源池,建议选择GPU 型号为 NVIDIA 4090,GPU 数量为 4 的资源,并设置节点数量为 2。 -
训练任务参数配置完成,点击确定,返回分布式训练任务列表,等待任务训练完成即可。
-
训练完成并成功后,根据训练任务启动脚本内容,可在存储与数据服务页面的
/Llama-Chinese/train/sft/save_folder路径下获取训练成功的模型。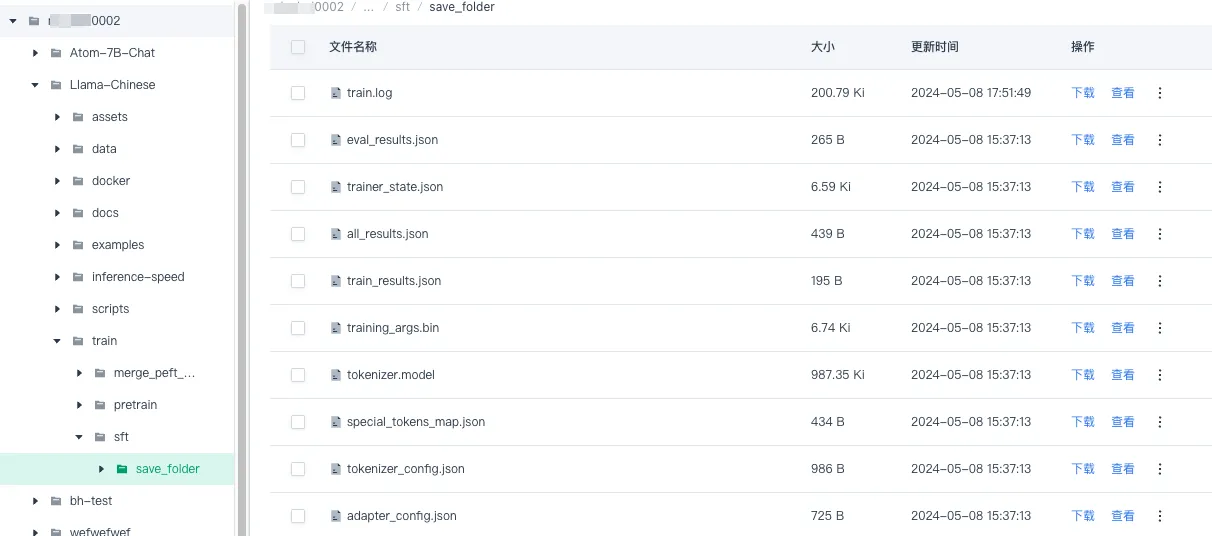
附录
示例启动脚本说明
本示例训练任务启动命令中使用的启动脚本为 torchrun_finetune_lora.sh,其内容可在存储与数据服务页面进行查看。
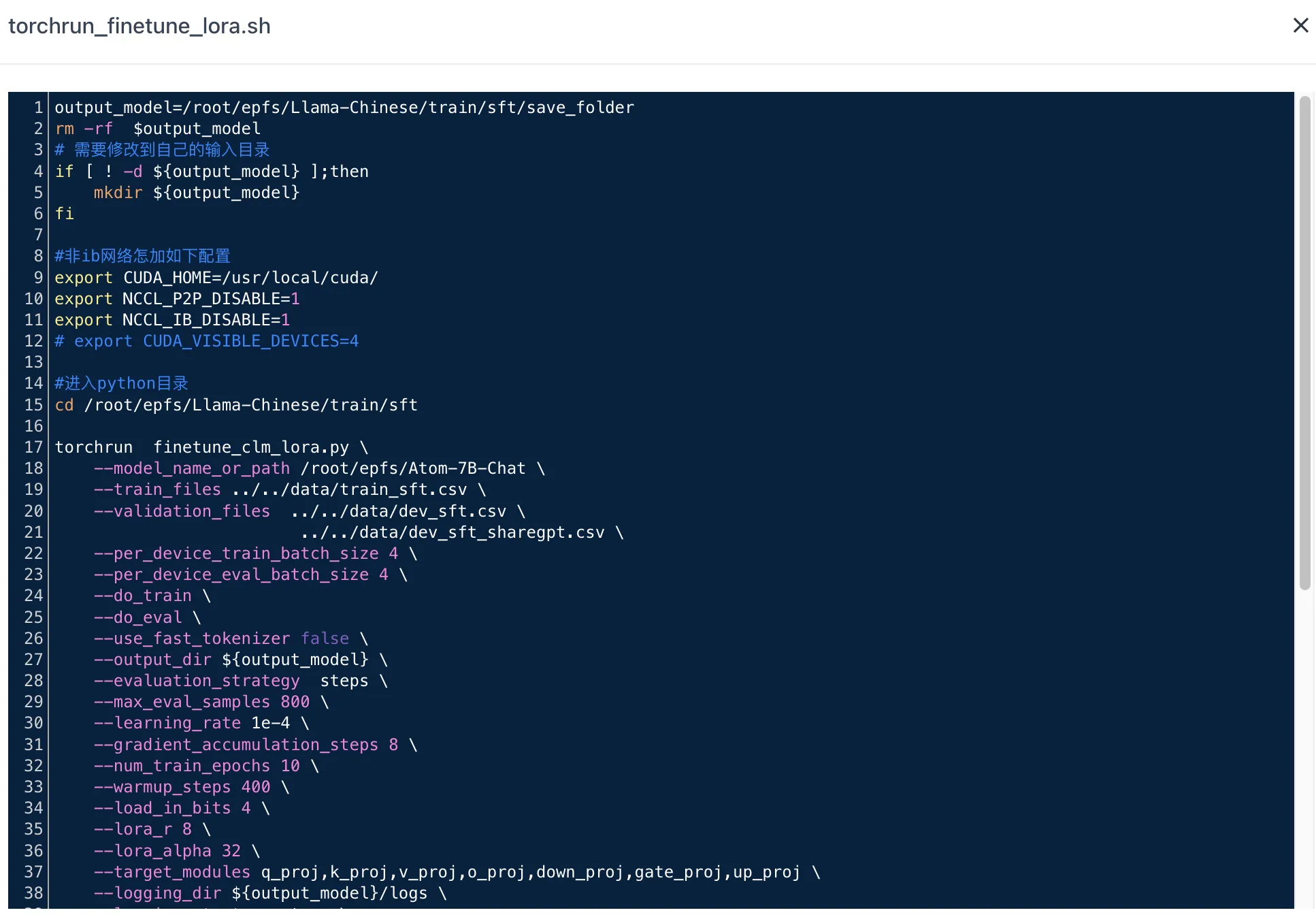
启动脚本中部分参数说明:
-
output_model:微调模型输出路径,此示例中为/Llama-Chinese/train/sft/save_folder,支持用户自定义。 -
model_name_or_path: 预训练模型路径,此示例中为/root/epfs/Atom-7B-Chat,即训练模型上传至文件存储中的路径。 -
train_files:训练数据集。 -
validation_files:验证数据集。