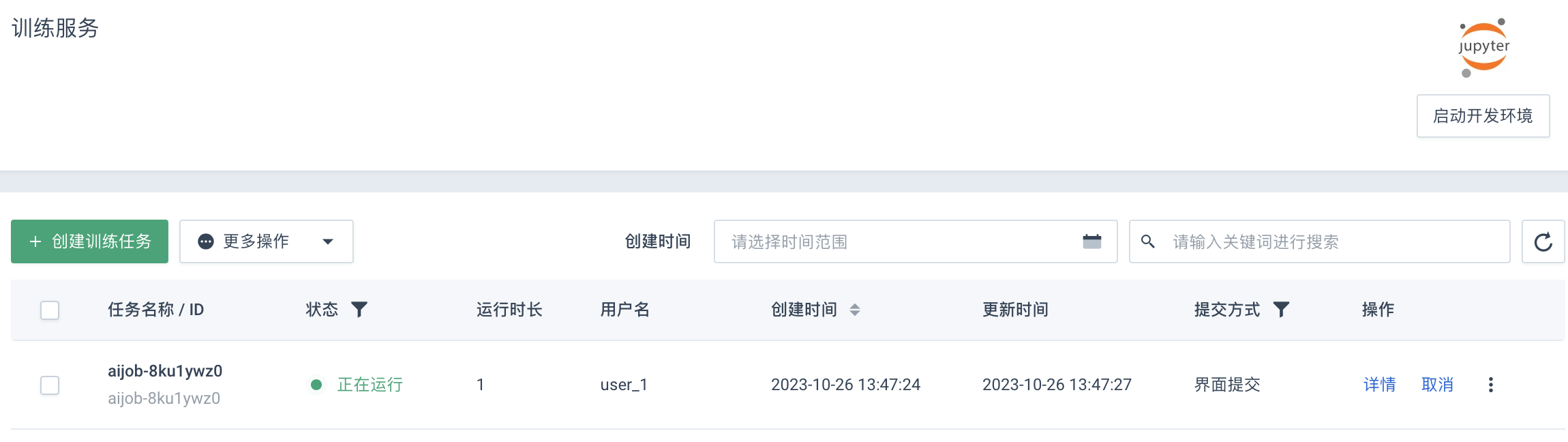
步骤二:创建训练任务
模型训练所需的代码和数据上传至集群之后,需要创建相应的训练任务,即提交相应的 AI 模型训练作业。
前提条件
-
已获取管理控制台账号和密码。
-
已完成个人实名认证且账户余额大于 0 元。
-
AI 算力集群已创建完成。
-
若需在外网下载资源,则相应计算节点或 AI 算力平台所在网络已绑定公网 IP。
操作步骤
-
登录管理控制台。
-
点击产品与服务 > 计算 > AI 算力平台,选择左侧导航栏中的训练服务。
-
点击创建训练服务,进入训练创建页面,选择运行环境。
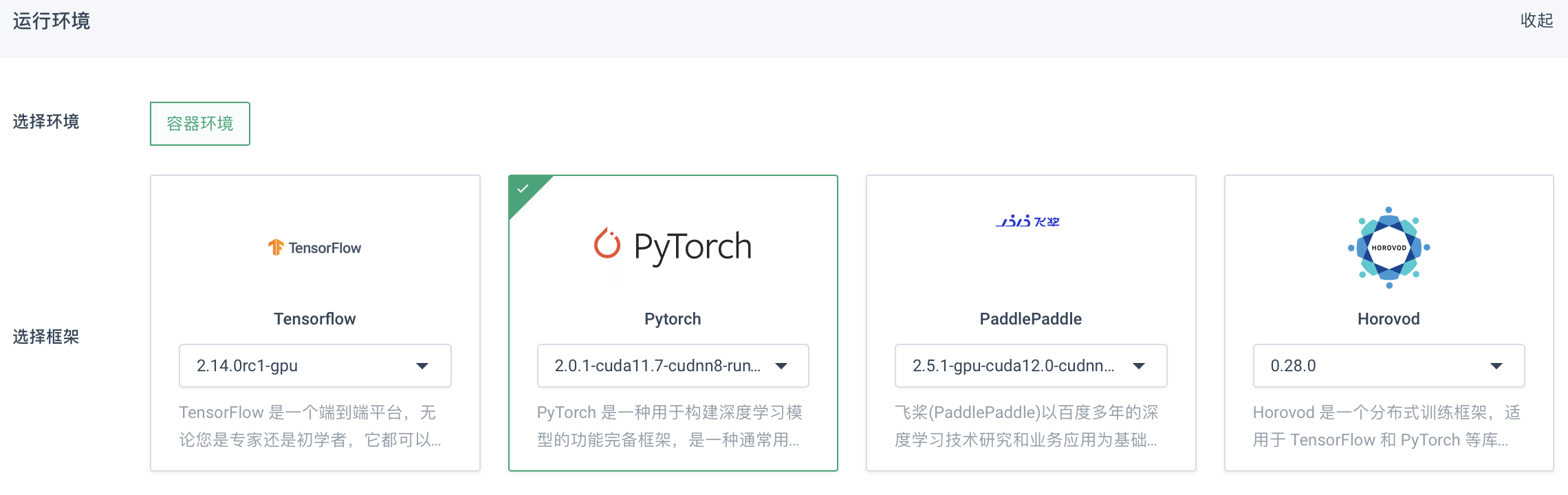
参数说明:
参数 说明 选择环境
容器环境,内置 Docker 工具,用户可随意选择镜像,且支持自定义镜像仓库。
选择框架
目前支持 PyTorch、TensorFlow、PaddlePaddle 或 Horovod 框架。
-
进行训练脚本配置。
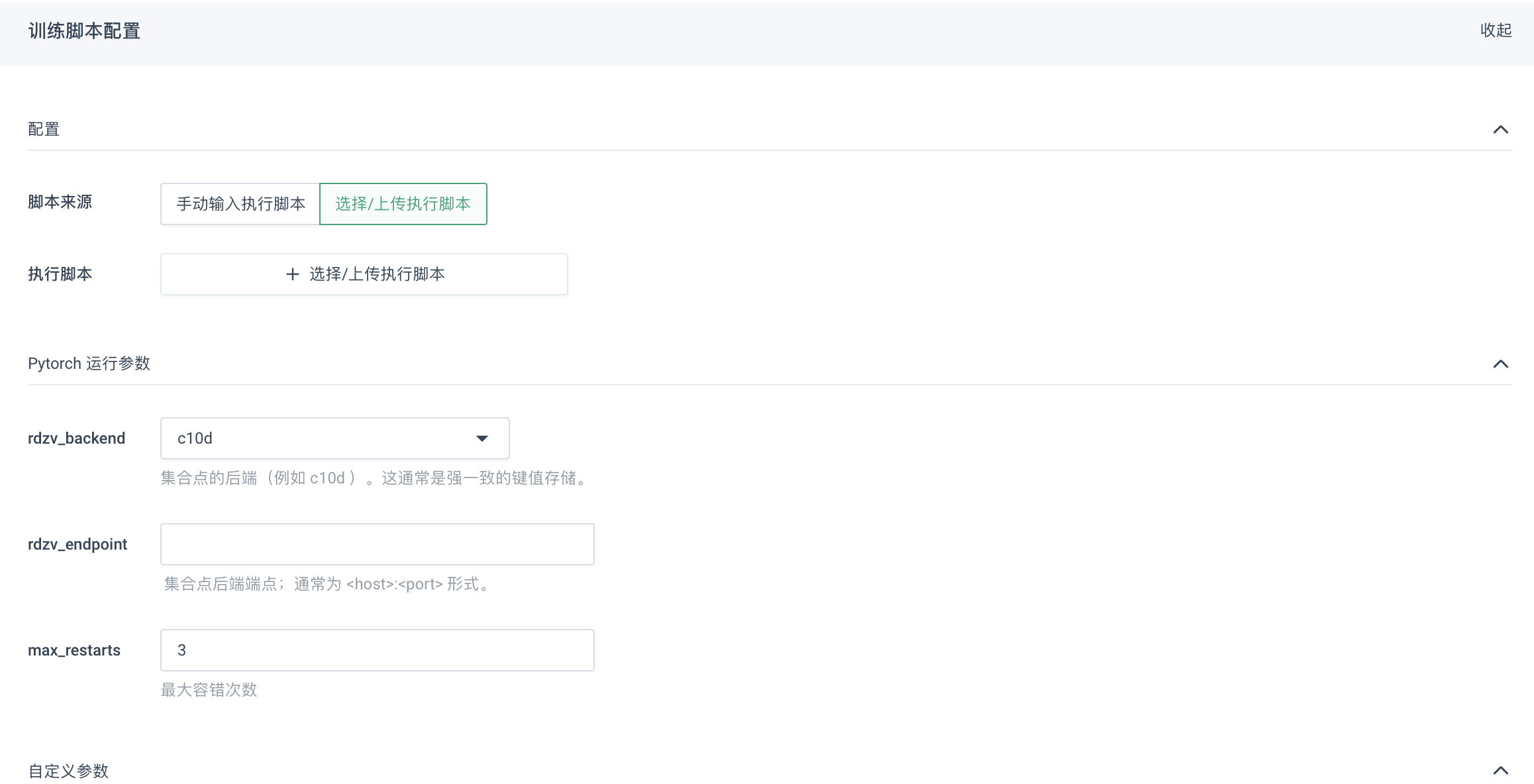
参数说明:
参数 说明 脚本来源
支持用户手动输入执行脚本或选择/上传执行脚本。
-
若使用手动输入执行脚本,需勾选手动输入执行脚本,根据实际情况选择工作目录,点击编辑图标,输入脚本名称,并在作业执行脚本框中输入相应的脚本内容,点击保存即可。
-
若使用上传相应执行文件的方式,需勾选选择/上传执行脚本,在作业执行脚本处,点击+选择/上传执行脚本。在弹出的选择命令文件的窗口中,点击二级目录,选择指定用户的目录。进入指定用户的目录下后,选择需执行的脚本文件,点击确定即可。若执行脚本文件未提前上传,则可点击上传本地文件,进行上传。
运行参数
根据所选架构不用,需要配置的参数也不同,用户可根据实际情况进行填写。配置参数说明
自定义参数
用户可根据实际需要配置深度学习所需参数。
-
-
进行资源配置。

参数说明:
参数 说明 任务名称
当前训练任务的名称,支持用户自定义。目前仅支持英文、数字和短横线,暂不支持中文字符。
训练资源
支持单节点训练或多节点分布式训练。
-
单节点训练:使用单一计算节点进行模型训练,即所有的数据和计算都在同一计算节点上进行。该方式适用于较小规模的数据集和简单模型,并且对计算资源的要求较低。
-
多节点分布式训练:是指将训练任务分发到多各计算节点上进行并行计算的方式。该方式中不同节点上的数据和计算可以同时进行,从而加快训练速度并提高模型的性能,适用于处理大规模数据集和复杂模型的训练任务。
GPU 卡数或节点
-
若训练资源选择单节点训练,则此处需配置 GPU 卡数,根据集群规模选择即可。
-
若训练资源选择多节点分布式训练,则此处需配置节点数,每个节点可使用的 GPU 卡数为当前节点的最大 GPU 卡数,根据集群规模选择即可。
-
-
点击立即创建,返回训练服务列表页面,等待训练任务运行完成即可。