使用 CLI 提交方式进行模型训练
更新时间:2024-03-26 15:03:08
PDF
本章节以容器环境中的 PyTorch 架构为例,详细介绍如何在 AI 算力平台使用 CLI 命令行提交方式完成单节点模型训练任务。
前提条件
-
已获取管理控制台账号和密码。
-
已完成个人实名认证且账户余额大于 0 元。
-
已准备好示例代码或数据,可参考附录内容。
-
使用 CLI 命令行形式提交训练任务,需登录集群后台。建议使用 JupyterLab 登录。
操作步骤
-
将示例训练代码或数据上传至集群的并行文件存储中,并记录相应的存储路径。
-
使用 JupyterLab 登录至集群后台。
-
进入示例代码
python.py所在路径。在后台终端页面,确认当前已处于相应目录下。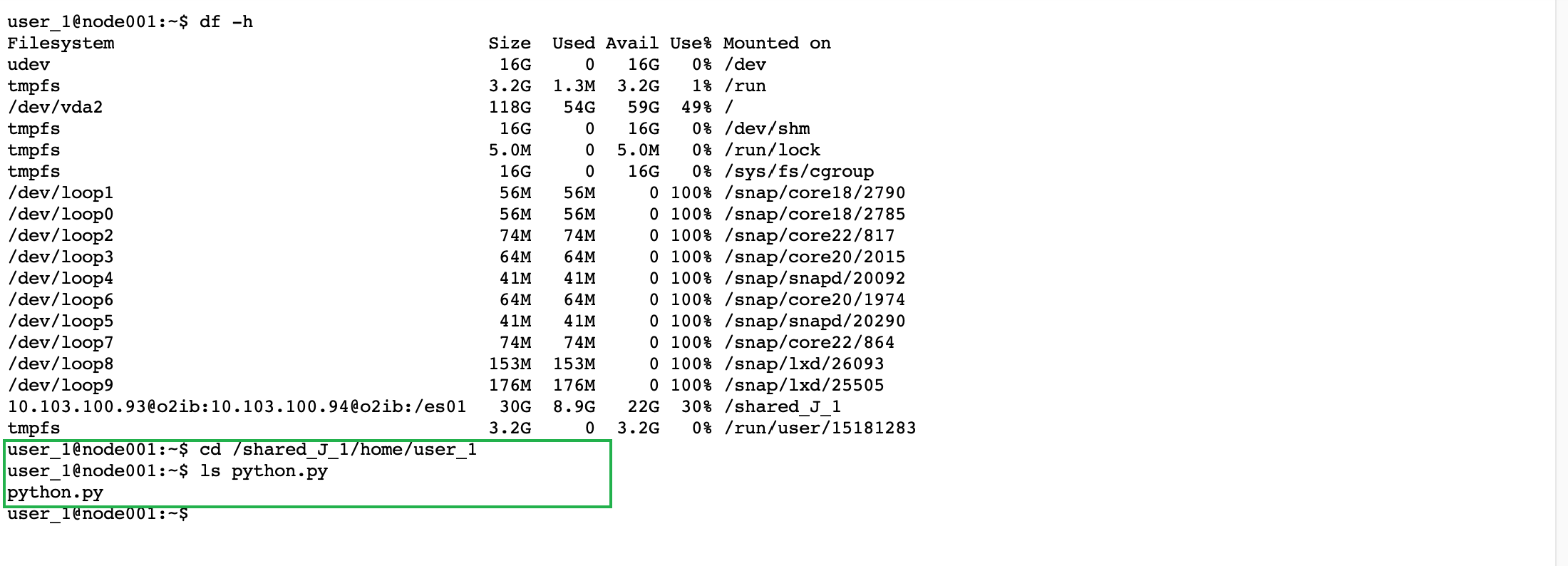
-
在示例代码所在路径下,创建
.slm格式的执行脚本。例如,创建名为python.slm的脚本。vim python.slm脚本示例内容如下:
#!/bin/bash #SBATCH --job-name=Job-rFJJr #SBATCH --nodes=1 #SBATCH --gpus-per-node=1 #SBATCH --ntasks-per-node=1 SINGULARITY_NOHTTPS=true singularity pull pytorch_2.0.1_cuda1.7_cudnn8_runtime.sif \ http://10.42.12.8:8080/pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime export MASTER_ADDR=$(scontrol show hostname ${SLURM_NODELIST} | head -n 1) export MASTER_PORT=40001 srun singularity exec --nv --bind type=bind,source=<your_mount_path>,destination=<your_mount_path> \ pytorch_2.0.1_cuda1.7_cudnn8_runtime.sif \ torchrun --nnodes=2 --nproc_per_node=1 \ --rdzv_id=$SLURM_JOBID --rdzv_backend=c10d \ --rdzv_endpoint=$MASTER_ADDR:$MASTER_PORT \ <your_python_training_script_path>脚本参数说明:
-
<your_mount_path>:为挂载至集群上的并行文件存储的共享目录,即文件列表中的根目录,本示例中为/shared_J_1。 -
<your_python_training_script_path>:为示例代码所在的路径,本示例中为/shared_J_1/home/user_1/python.py。
-
-
.slm格式的执行脚本创建完成并保存后,执行如下命令,提交训练任务至集群。sbatch python.slm回显示例如下,将返回当前任务的 ID:
Submitted batch job 21 -
查看训练任务状态,可通过以下两种方式。
-
方法一
在集群后台执行如下命令,查看对应任务 ID 的
State值即可。sacct -
方法二
在训练服务页面,可查看上述任务显示在训练服务列表内。
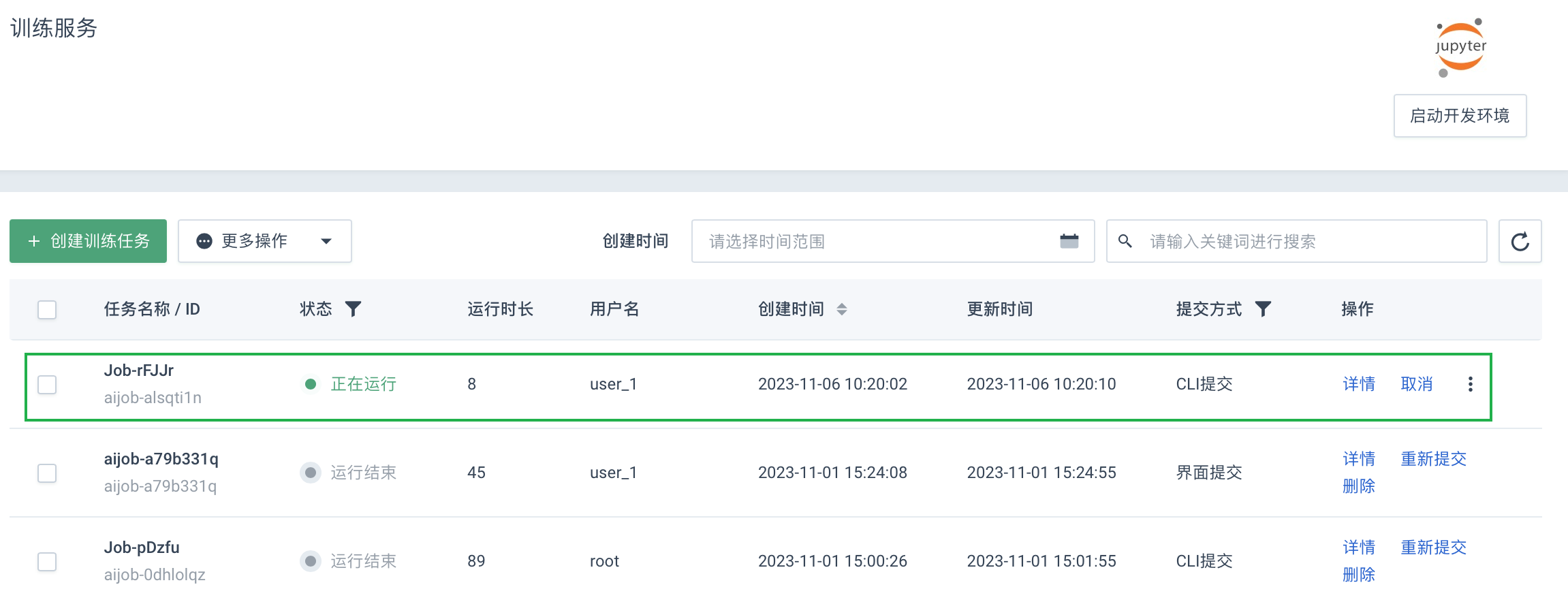
-
-
等待任务执行完成,点击相应任务操作列内的详情,进入其详细信息页面,查看或下载相应的标准输出日志或错误输出日志。
附录
示例训练代码 python.py 文件内容如下,可点击此处直接下载。
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# [*] Packages required to import distributed data parallelism
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
import subprocess
"""Start DDP code with "srun --partition=openai -n8 --gres=gpu:8 --ntasks-per-node=8 --job-name=slrum_test"
"""
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, optimizer, device):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# [*] only print log on rank 0
if dist.get_rank() == 0 and batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn, device):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
# [*] only print log on rank 0
print_only_rank0(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
def print_only_rank0(log):
if dist.get_rank() == 0:
print(log)
if __name__ == '__main__':
# [*] initialize the distributed process group and device
# rank, local_rank, world_size, device = setup_DDP(verbose=True)
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.node id : {os.getenv('SLURM_NODEID')}")
print("torch.cuda.device_count() : " + str(torch.cuda.device_count()))
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
# initialize dataset
training_data = datasets.FashionMNIST(root="data", train=True, download=True, transform=ToTensor())
test_data = datasets.FashionMNIST(root="data", train=False, download=True, transform=ToTensor())
# initialize data loader
# [*] using DistributedSampler
batch_size = 64 // dist.get_world_size() # [*] // world_size
train_sampler = DistributedSampler(training_data, shuffle=True) # [*]
test_sampler = DistributedSampler(test_data, shuffle=False) # [*]
train_dataloader = DataLoader(training_data, batch_size=batch_size, sampler=train_sampler) # [*] sampler=...
test_dataloader = DataLoader(test_data, batch_size=batch_size, sampler=test_sampler) # [*] sampler=...
# initialize model
model = NeuralNetwork().to(device_id) # copy model from cpu to gpu
# [*] using DistributedDataParallel
model = DDP(model, device_ids=[device_id], output_device=device_id) # [*] DDP(...)
print_only_rank0(model) # [*]
# initialize optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# train on multiple-GPU
epochs = 5
for t in range(epochs):
# [*] set sampler
train_dataloader.sampler.set_epoch(t)
test_dataloader.sampler.set_epoch(t)
print_only_rank0(f"Epoch {t + 1}\n-------------------------------") # [*]
train(train_dataloader, model, loss_fn, optimizer, device_id)
test(test_dataloader, model, loss_fn, device_id)
print_only_rank0("Done!") # [*]
# [*] save model on rank 0
if dist.get_rank() == 0:
model_state_dict = model.state_dict()
torch.save(model_state_dict, "model.pth")
print("Saved PyTorch Model State to model.pth")