使用界面提交方式进行模型训练
本章节以容器环境中的 PyTorch 架构为例,详细介绍如何在 AI 算力平台使用界面提交方式完成单节点模型训练任务。
前提条件
-
已获取管理控制台账号和密码。
-
已完成个人实名认证且账户余额大于 0 元。
-
已准备好示例代码或数据,可参考附录内容。
操作步骤
-
将示例训练代码或数据上传至集群的并行文件存储中。
-
登录管理控制台,点击产品与服务 > 计算 > AI 算力平台,选择左侧导航栏中的训练服务,并点击创建训练任务。
-
在创建训练任务窗口中,配置运行环境,选择容器环境以及 PyTorch 框架。
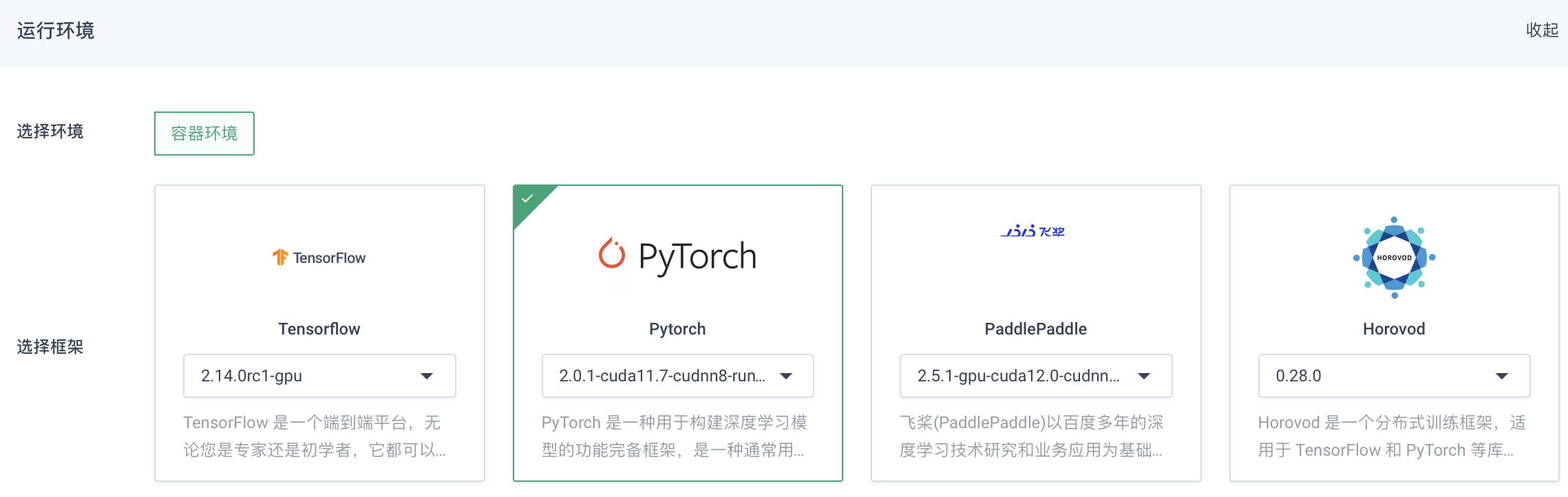
-
进行训练脚本配置。
-
脚本来源选择选择/上传执行脚本,点击上传脚本按钮。
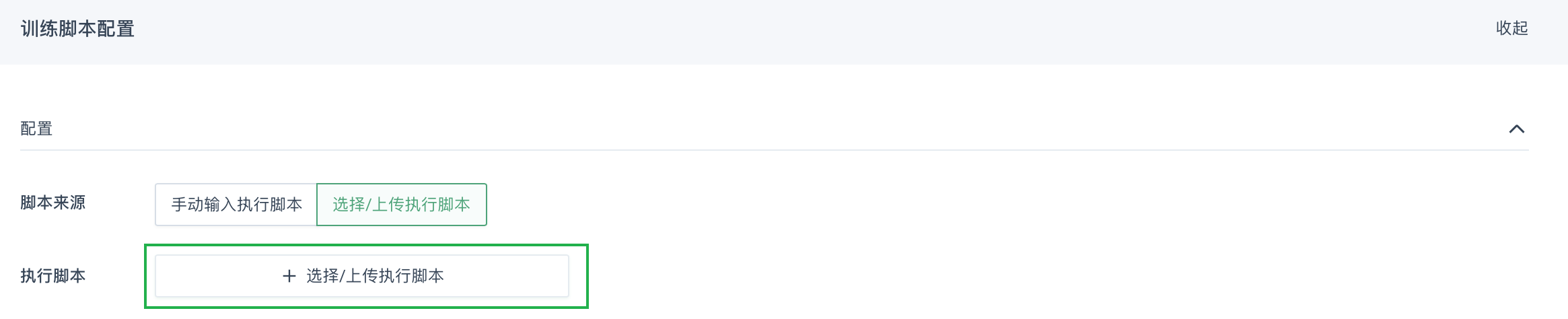
-
在弹出的选择命令文件窗口中,勾选待执行的脚本文件,如
tourch_ddp.py文件,点击确定即可。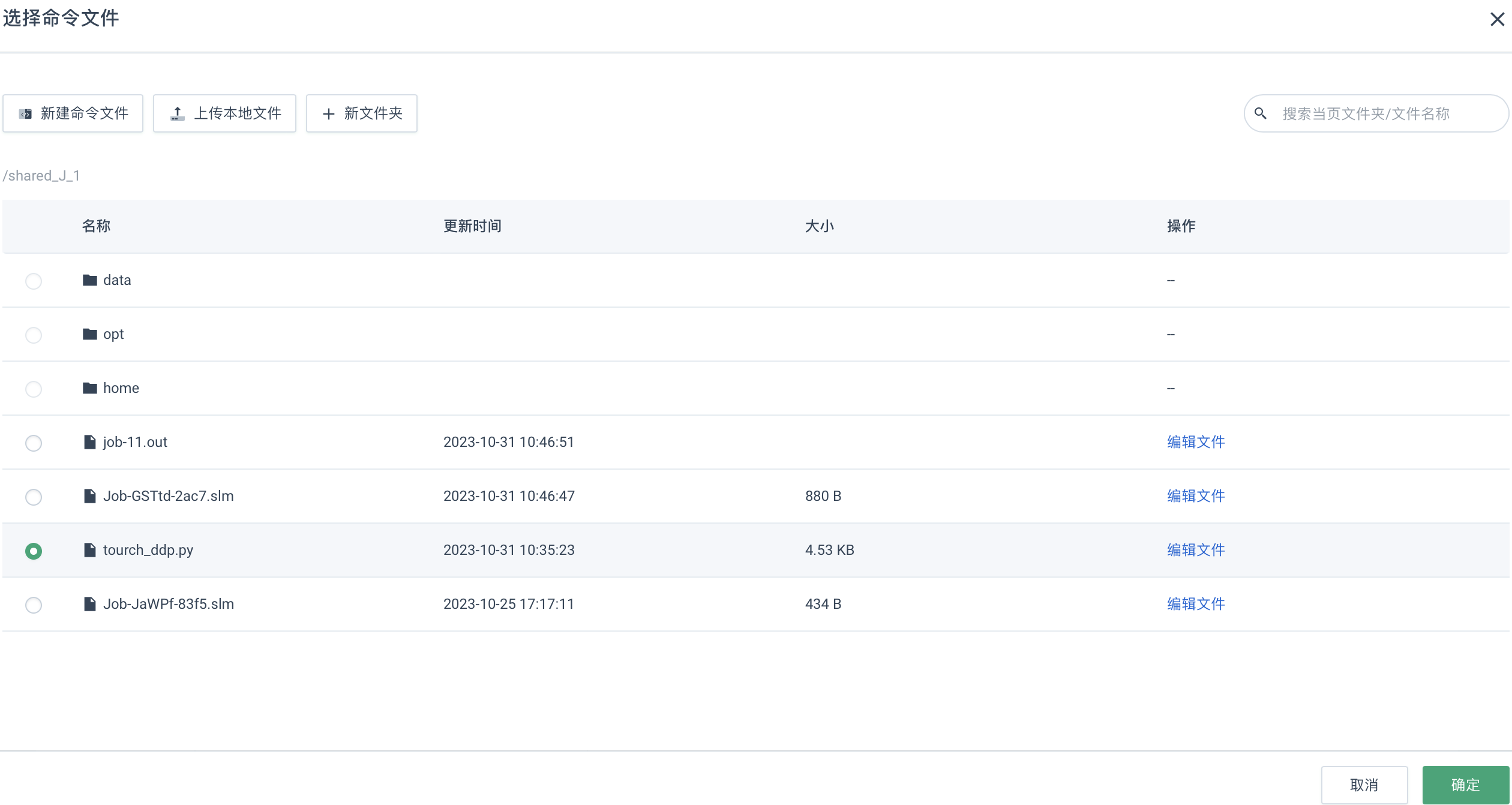
-
PyTorch 运行参数配置,其中
rdzv-backend设置为c10d,rdzv_endpoint为空,max-restarts设置为3,requirement为空即可。注意 此处参数配置仅针对当前示例,用户可根据实际情况做出相应修改。
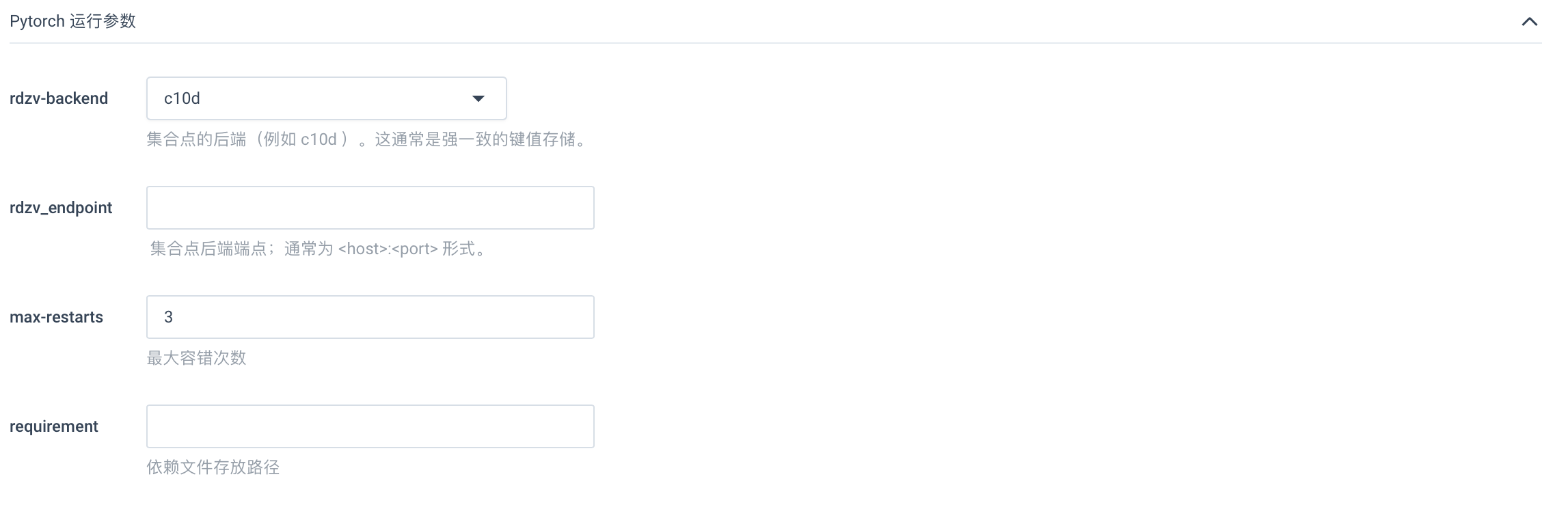
-
设置自定义参数。 点击添加参数,在输入框中填写相应参数值,如
--batch-size=256。注意 此处参数配置仅针对当前示例,用户可根据实际情况做出相应修改。
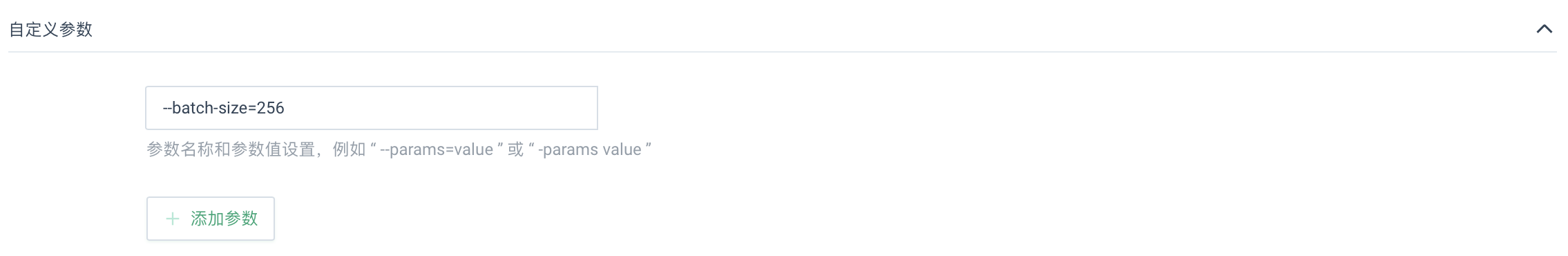
-
-
进行资源配置,根据实际需要自定义任务名称,选择训练资源为
单节点训练,GPU 卡数设置为1。说明 任务名称目前仅支持英文、数字和短横线,暂不支持中文字符。

-
点击立即创建,即可提交训练任务至 AI 算力集群。
-
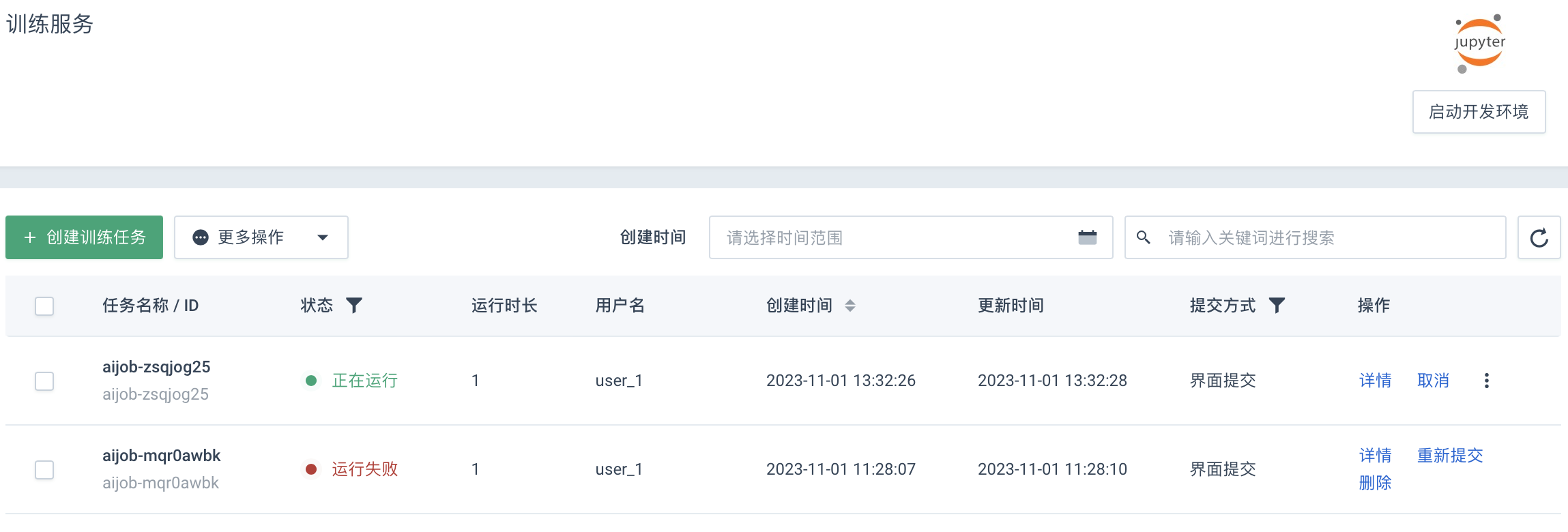
页面返回训练服务页面,新创建的训练任务已显示在列表内。
-
等待任务运行结束,在训练列表内,点击指定任务操作列内的详情,进入其详细信息页面。
-
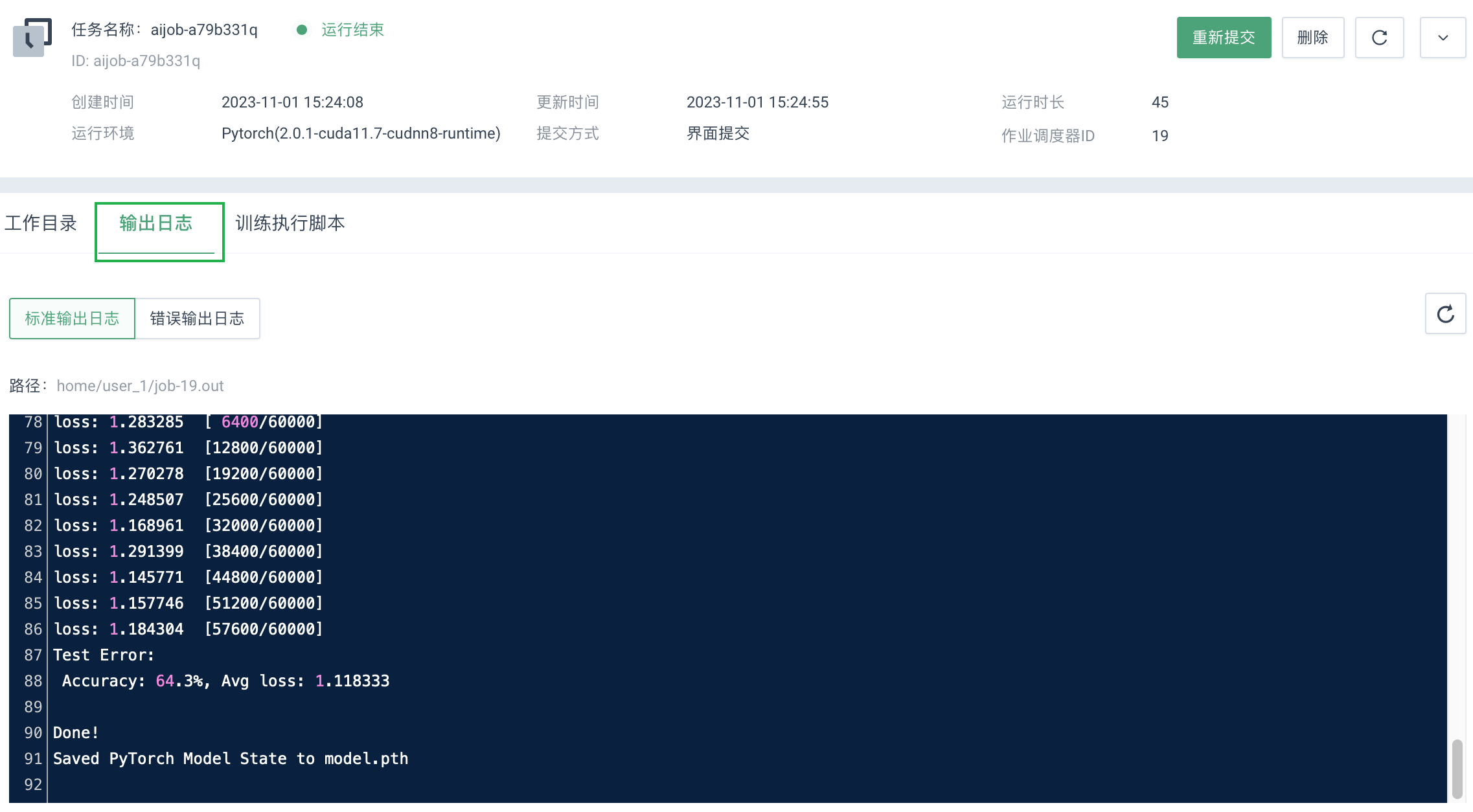
在任务详情页面,选择输出日志页签,可查看相应任务的标准输出日志。若任务运行失败也可在该详情页面,查看相关错误输出日志。
附录
示例训练代码 tourch_ddp.py 文件内容如下,也可直接点击此处下载。
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# [*] Packages required to import distributed data parallelism
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
import subprocess
"""Start DDP code with "srun --partition=openai -n8 --gres=gpu:8 --ntasks-per-node=8 --job-name=slrum_test"
"""
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, optimizer, device):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
# [*] only print log on rank 0
if dist.get_rank() == 0 and batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn, device):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device) # copy data from cpu to gpu
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
# [*] only print log on rank 0
print_only_rank0(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
def print_only_rank0(log):
if dist.get_rank() == 0:
print(log)
if __name__ == '__main__':
# [*] initialize the distributed process group and device
# rank, local_rank, world_size, device = setup_DDP(verbose=True)
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.node id : {os.getenv('SLURM_NODEID')}")
print("torch.cuda.device_count() : " + str(torch.cuda.device_count()))
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
# initialize dataset
training_data = datasets.FashionMNIST(root="data", train=True, download=True, transform=ToTensor())
test_data = datasets.FashionMNIST(root="data", train=False, download=True, transform=ToTensor())
# initialize data loader
# [*] using DistributedSampler
batch_size = 64 // dist.get_world_size() # [*] // world_size
train_sampler = DistributedSampler(training_data, shuffle=True) # [*]
test_sampler = DistributedSampler(test_data, shuffle=False) # [*]
train_dataloader = DataLoader(training_data, batch_size=batch_size, sampler=train_sampler) # [*] sampler=...
test_dataloader = DataLoader(test_data, batch_size=batch_size, sampler=test_sampler) # [*] sampler=...
# initialize model
model = NeuralNetwork().to(device_id) # copy model from cpu to gpu
# [*] using DistributedDataParallel
model = DDP(model, device_ids=[device_id], output_device=device_id) # [*] DDP(...)
print_only_rank0(model) # [*]
# initialize optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
# train on multiple-GPU
epochs = 5
for t in range(epochs):
# [*] set sampler
train_dataloader.sampler.set_epoch(t)
test_dataloader.sampler.set_epoch(t)
print_only_rank0(f"Epoch {t + 1}\n-------------------------------") # [*]
train(train_dataloader, model, loss_fn, optimizer, device_id)
test(test_dataloader, model, loss_fn, device_id)
print_only_rank0("Done!") # [*]
# [*] save model on rank 0
if dist.get_rank() == 0:
model_state_dict = model.state_dict()
torch.save(model_state_dict, "model.pth")
print("Saved PyTorch Model State to model.pth")