创建离线-批量同步作业(向导模式)
数据集成作业支持向导模式和脚本模式。本小节主要介绍向导模式。
前提条件
-
已添加数据源至目标工作空间。
-
目标工作空间已创建计算集群。
开发流程
-
创建离线-批量同步作业。
-
开发作业。
-
选择数据来源。
-
选择数据目的。
-
配置字段映射。
-
选择计算集群。
-
通道控制。
-
-
配置作业调度。
-
发布作业。
创建离线-批量同步作业
-
登录管理控制台。
-
选择产品与服务 > 大数据服务 > 大数据工作台,进入大数据工作台概览页面。
-
在左侧导航选择工作空间,进入工作空间页面。
-
在目标工作空间选择数据开发 > 作业开发,进入作业开发页面。
-
点击创建作业,进入创建作业页面。
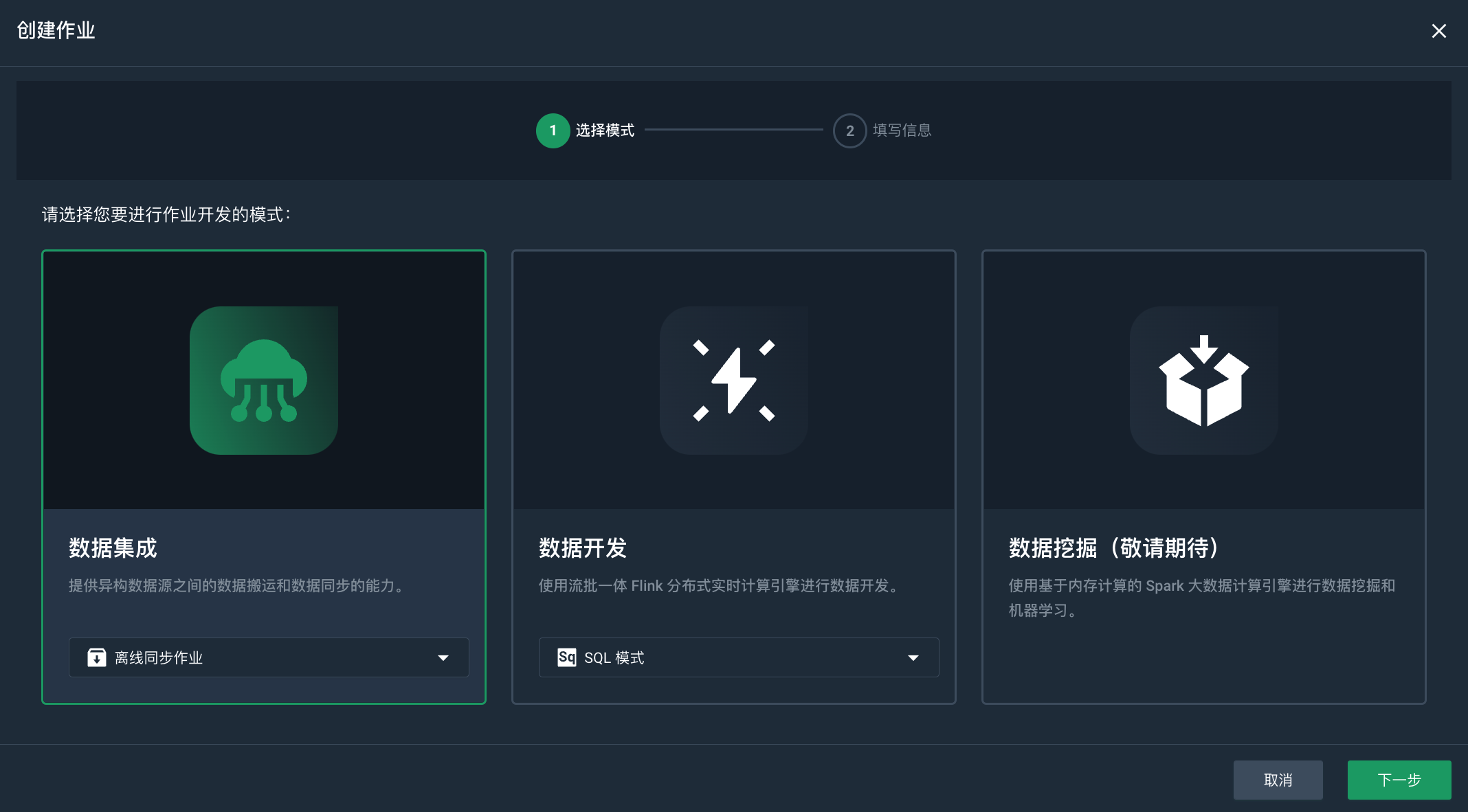
-
选择离线-批量同步作业,点击下一步。
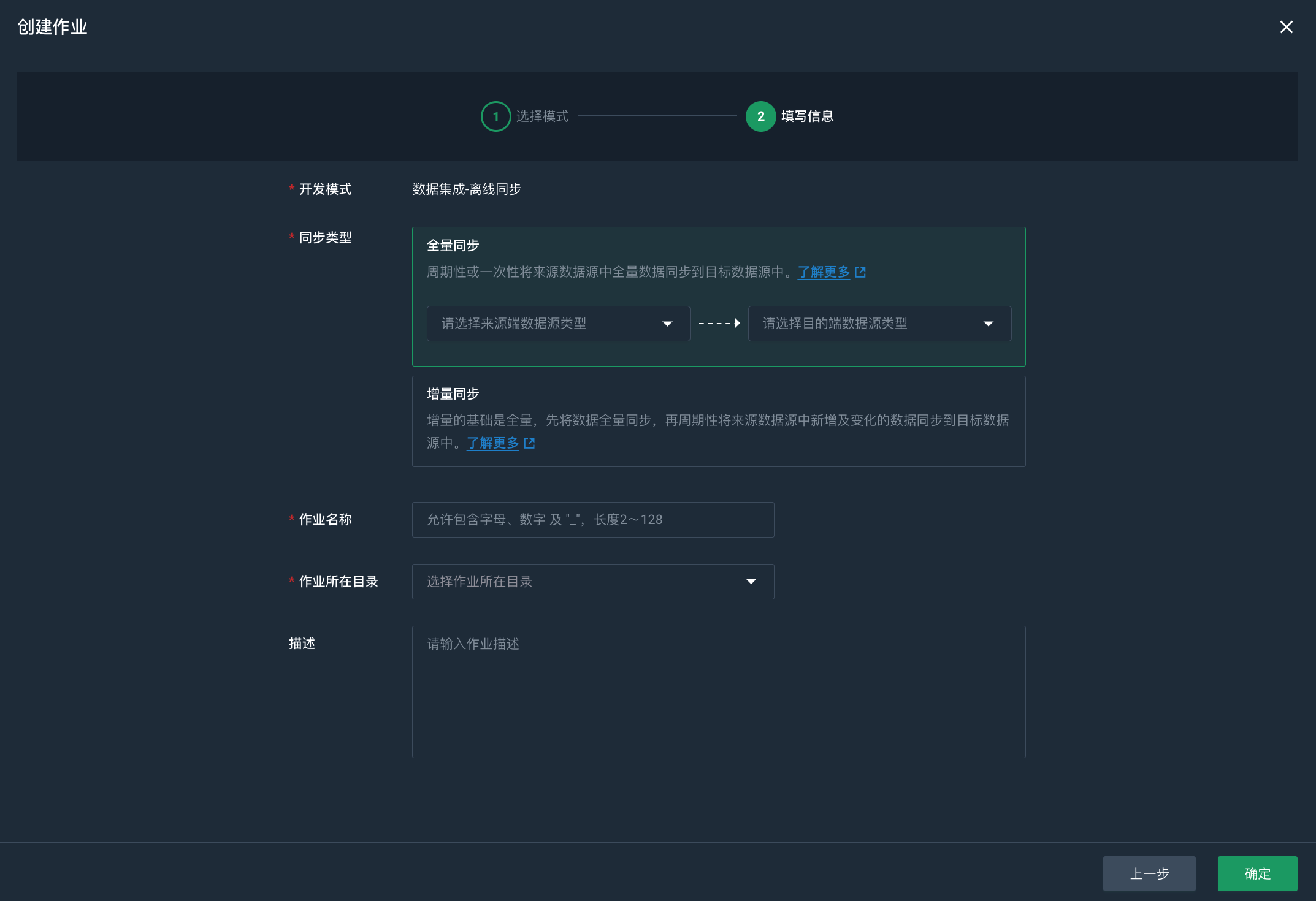
-
配置作业相关信息。
参数 参数说明 开发模式
作业开发模式,点击上一步可以修改。
同步类型
作业名称
创建的作业名称,您可以自定义。
作业所在目录
选择作业所在目录。数据集成作业只能在数据集成目录和其子目录下。
描述
作业的描述信息,您可以自定义。
-
点击确定,开始创建作业。
开发作业

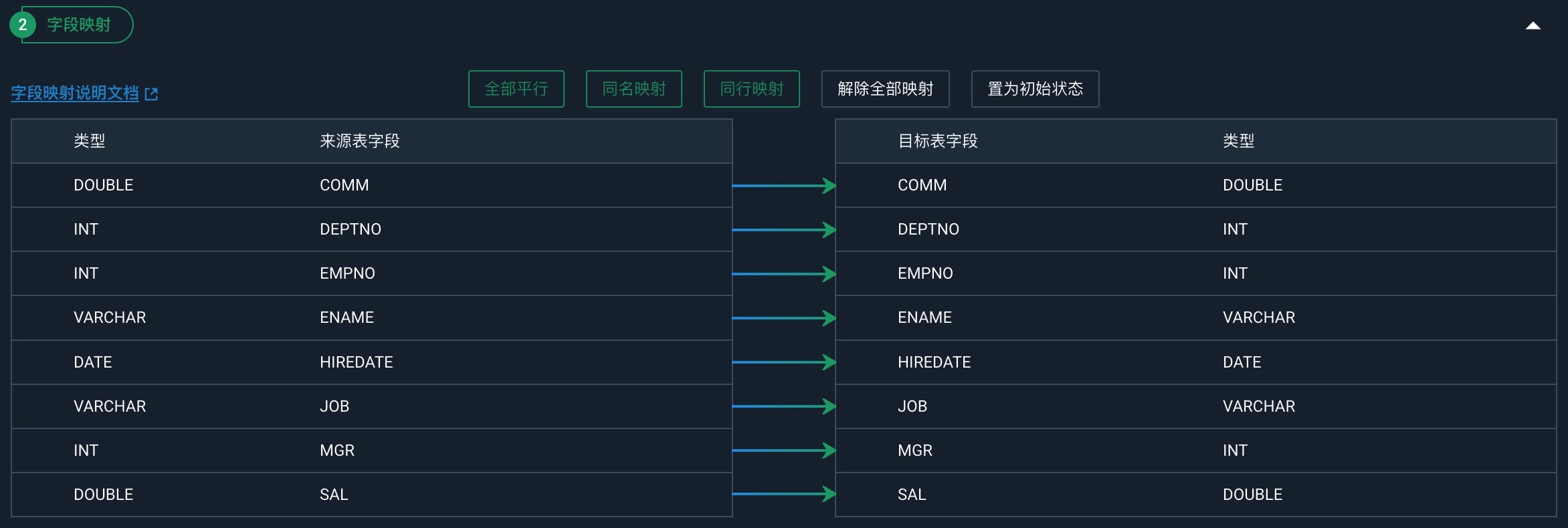
配置字段映射
选择数据来源和数据目的后,您需要指定来源表字段和目的端字段的映射关系。您可以选择全部平行、同名映射、同行映射、解除全部映射或置为初始状态。
选择数据来源后,系统自动加载出来源表字段和类型。
-
来源表字段:不可以修改。
-
类型:可以修改。支持的数据类型请参见配置数据来源。
选择数据目的后,系统自动加载出来目标表字段和类型。
-
目标表字段:不可以修改。
-
类型:不可以修改。支持的数据类型请参见配置数据目的。
| 操作 | 说明 |
|---|---|
全部平行 |
点击全部平行,可以自动将已建立的映射关系的字段调整到同行。 |
同名映射 |
点击同名映射,可以根据名称建立相应的映射关系,请注意匹配数据类型。 |
同行映射 |
点击同行映射,可以在同行建立相应的映射关系,请注意匹配数据类型。 |
解除全部映射 |
点击解除全部映射,可以解除已建立的映射关系。 |
置为初始状态 |
点击置为初始状态,可以解除已建立的映射关系并恢复字段排序为初始状态。 |
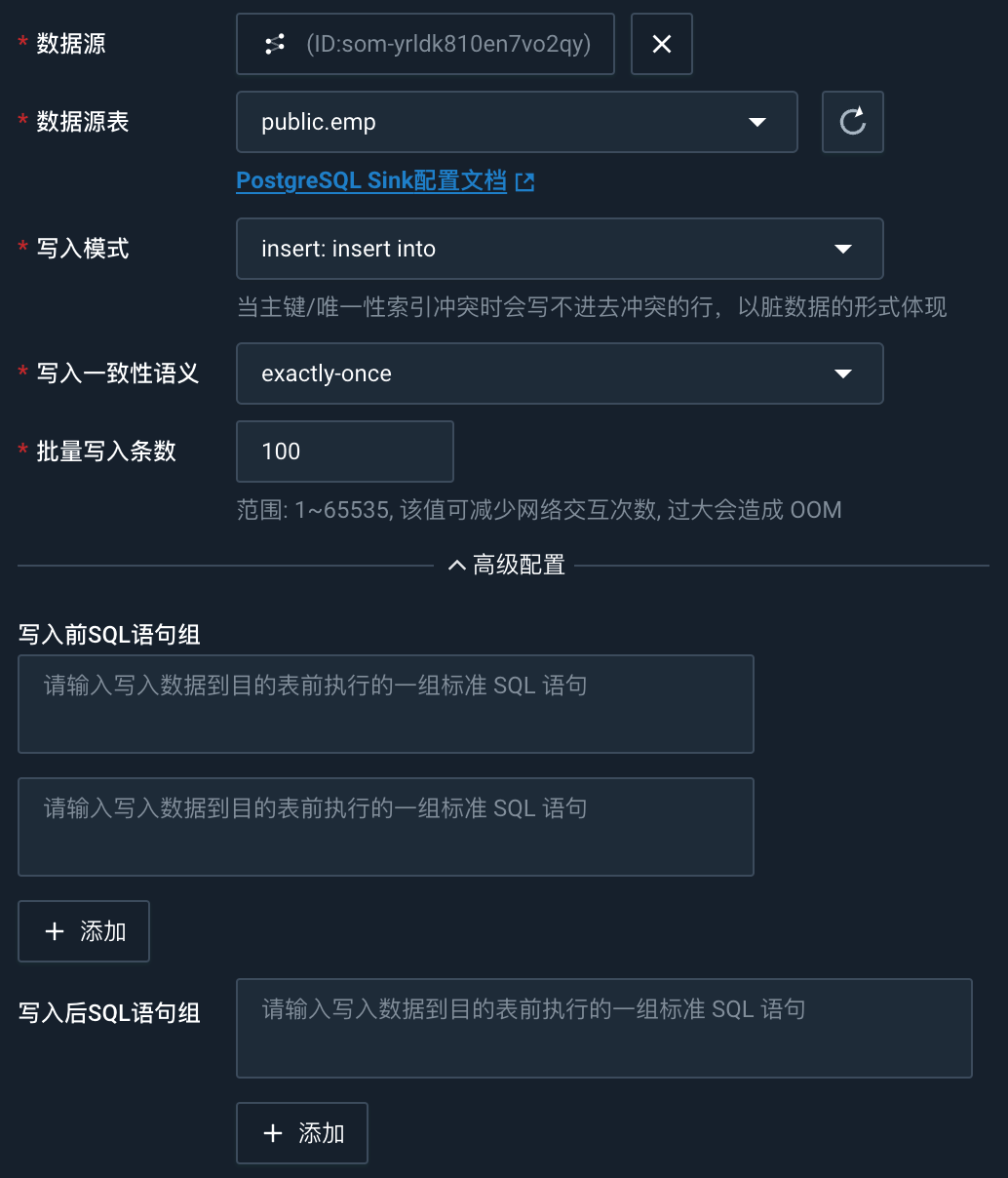
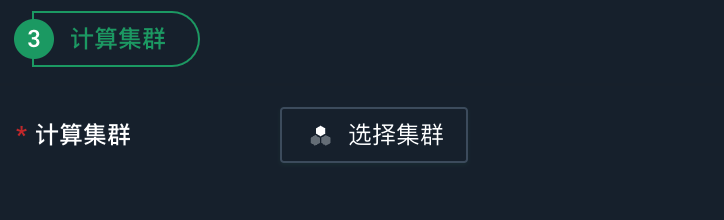
选择计算集群
点击选择集群,在弹出的对话框中选择已创建好的计算集群;也可以在对话框中点击计算集群列表,进入计算集群页面,创建新的计算集群。
| 注意 |
|---|
若您没有提前创建计算集群,点击计算集群列表后,已配置的数据源信息将会丢失。 |
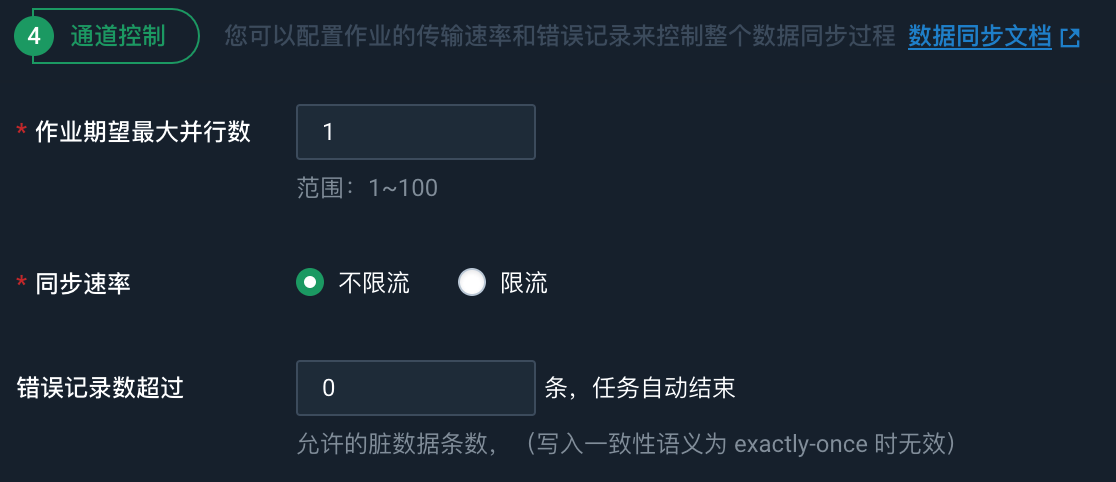
通道控制
| 参数 | 说明 |
|---|---|
作业期望最大并行数 |
数据同步任务内,可以从源并行读取或并行写入数据存储端的最大线程数。向导模式通过界面化配置并发数,指定任务所使用的并行度。 |
同步速率 |
设置同步速率可以保护读取端数据库,以避免抽取速度过大,给源库造成太大的压力。同步速率建议限流,结合源库的配置,请合理配置抽取速率。 |
错误记录数 |
设置允许的脏数据条数,当脏数据超过设置的阈值时,作业将自动结束运行。 |
保存作业
完成以上配置后,点击保存,保存作业。
发布作业
-
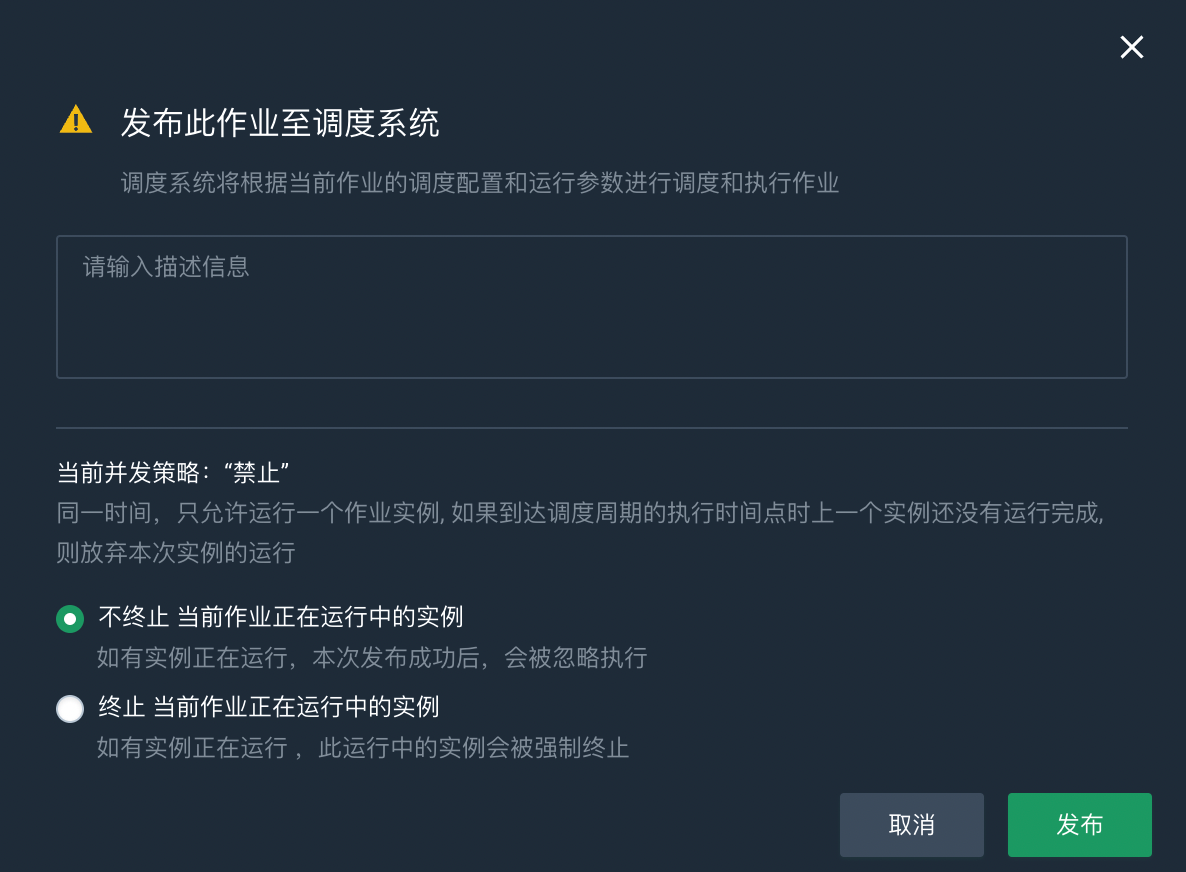
点击发布,弹出发布调度任务对话框。
-
您可以根据实际情况选择是否终止当前作业正在运行中的实例,如果终止当前作业正在运行中的实例,运行中的作业实例会立即被强制终止。
-
点击发布,发布作业。发布作业时也会对代码进行语法检查,需要一定的时间,请耐心等待。
作业发布成功后,您可以前往运维中心查看已发布作业和作业实例。